
Sistemas distribuídos vão falhar, todos nós sabemos. Em algum momento os sistemas que construímos deixarão nossos usuários insatisfeitos devido a erros e instabilidades.
Sábado, por volta das oito horas da noite, ouço a minha filha me chamar: “Papaaai, você pode trocar o desenho para mim? Esse negócio tá travando”.
Por “esse negócio”, a minha pequena filha quis dizer o streaming de vídeos de uma empresa gigante de animações. Mesmo com investimentos de milhões de dólares e um time grande de profissionais, usando as mais novas metodologias ágeis, as melhores práticas de SRE em uma estrutura cloud native escalável e altamente resiliente.
Nada disso resolveu os rigorosos padrões de P99 da minha filha – que só queria conseguir assistir seu desenho de princesas sem que o vídeo travasse.

Big techs como Amazon, Facebook, Google e Microsoft, mesmo investindo centenas de milhões de dólares, frequentemente apresentam comportamentos indesejáveis em produção.
Mesmo com avanços gigantescos nos últimos anos na cultura de boas práticas, construir sistemas distribuídos não é algo simples – e principalmente, livre de falhas.
No artigo de hoje, abraço a missão de conversarmos sobre sistemas distribuídos, suas características, problemas, como podemos medir sua disponibilidade e algumas técnicas básicas de engenharia de software para resolvermos alguns desafios comuns de comunicação em um ambiente distribuído.
Vamos lá!
O que são sistemas distribuídos?

Segundo Andrew Tanenbaum e Maarten van Steen, em seu livro Distributed Systems, podemos definir um sistema distribuído como:
“um sistema cujo seus componentes estão localizados em diferentes computadores pela rede, onde eles comunicam e coordenam as suas ações através da troca de mensagens de um sistema para o outro”
Andrew S. Tanenbaum; Maarten van. Steen Distributed systems: principles and paradigms.
O grande benefício dos sistemas distribuídos é reduzir os riscos envolvidos em ter um único ponto de falha em sua arquitetura, aumentando a confiabilidade e tolerância a falhas em sua solução.
Outro ponto em comum em sistemas distribuídos modernos é a capacidade de escalar rapidamente assim que ocorrer uma demanda maior de uso, aumentando os recursos computacionais em tempo real, escalando a sua performance e reduzindo o tempo necessário para executar suas tarefas.
Quais são as principais características de sistemas distribuídos?
Em geral, podemos encontrar as seguintes características em sistemas distribuídos:
Escalabilidade: a habilidade de um sistema aumentar a sua capacidade de atendimento diante de uma demanda maior é fundamental em sistemas distribuídos, sendo possível adicionar maior processamento ou nós na rede assim que necessário;
Concorrência: é esperado que os componentes que compõe sistemas distribuídos possam funcionar simultaneamente;
Disponibilidade / tolerância a falha: se um nó falhar, os demais nós em sistemas distribuídos devem continuar a operação das tarefas sem que haja uma interrupção do sistema como um todo;
Transparência: um usuário ou sistema externo deve enxergar sistemas distribuídos como uma só unidade computacional. As partes internas que compõe sistemas distribuídos não são de interesse dos agentes externos, e portanto, devem estar ocultas dos mesmos;
Heterogeneidade: é bastante comum que sistemas distribuídos sejam compostos por nós ou componentes com diferentes hardwares, sistemas operacionais, runtimes, timeouts, entre outros;
Assincronismo: outra característica frequentemente desejada é que os componentes de sistemas distribuídos possam trocar mensagens de maneira assíncrona sempre que possível, evitando a retenção de recursos durante a espera de uma resposta de outro componente;
Redundância: sistemas distribuídos devem ser capazes de lidar com a existência de recursos em redundância e, portanto, capazes de compartilhar mensagens garantindo a consistência entre diferentes componentes (podendo ser hardware ou software). Assim, os sistemas distribuídos se beneficiam de melhores modelos de tolerância a falhas, confiabilidade e disponibilidade;
Como definimos falhas em sistemas distribuídos?
Um sistema falha quando ele apresenta um comportamento diferente do que se espera. Depois que uma falha em um sistema se manifesta, tornando-se visível e ativa, ela gera erros que podem se propagar causando impactos parciais ou integrais. Em outras palavras: erros são manifestações de falhas em um sistema.
Componentes que possuem falhas em seu sistema distribuído (podendo ser em software ou hardware), produzem erros que levam a inconsistência ou indisponibilidade do sistema como um todo ou de parte dele.
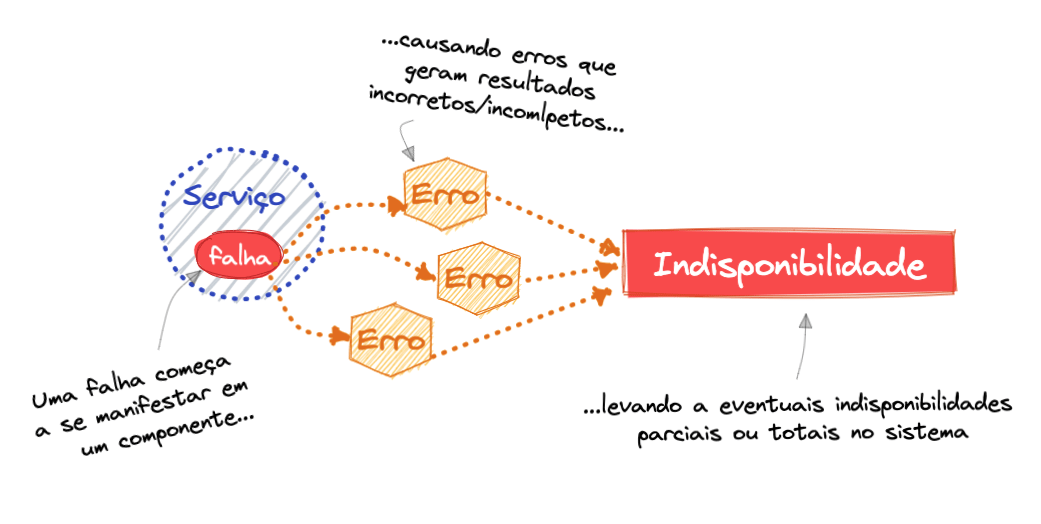
Um erro não tratado vindo de uma falha em um componente na sua arquitetura pode gerar impactos percebidos em todo o seu sistema. Aliás, a lista de possíveis fontes de falhas é praticamente interminável, passando por itens de software, hardware, ações humanas e outras.
Em síntese, podemos dividir a natureza das falhas em três grandes grupos: falhas transientes, intermitentes ou permanentes.
| Falhas transientes | Falhas intermitentes | Falhas permanentes |
|---|---|---|
 |  |  |
| Acontecem uma única vez em uma janela de tempo, não sendo detectadas novamente. Falhas transientes são difíceis de serem tratadas pois dificilmente teremos a repetição do contexto que possibilita a detecção delas. | Diferente das falhas transientes, as intermitentes reaparecem com alguma frequência. Um exemplo de falhas intermitentes são problemas de perda de pacotes causados por hardwares com problemas em sua rede, causando inconsistência nas mensagens. | São aquelas que uma vez iniciadas, elas não vão embora até que haja uma ação específica de tratamento contra elas. Um exemplo clássico são bugs em código que causam o consumo indiscriminado de memória até que haja o esgotamento da memória RAM, derrubando a instância do serviço. |
Falácias sobre computação distribuída
Construir sistemas distribuídos com um nível satisfatório de confiabilidade não é uma tarefa fácil. Mesmo em um cenário “simples” (com poucos elementos na rede), existem pontos de atenção importantes ocultos pela suposta baixa complexidade do sistema.
Assim, ao construir sistemas distribuídos, é essencial termos em mente que não podemos assumir que tudo acontecerá o tempo todo dentro das nossas expectativas. Portanto. precisamos ficar atentos a falhas e indisponibilidades inesperadas em componentes essenciais para execução dos nossos sistemas.

Laurence Peter Deutsch, em 1994 enquanto ainda trabalhava na extinta Sun Microsystems, publicou o “Fallacies of distributed computing“. Neste artigo ele aborda oito expectativas relacionadas a sistemas distribuídos que frequentemente se mostram falsas verdades. São elas:
1 – Rede é um recurso confiável.
Não devemos assumir que a rede de que os nossos sistemas dependem serão sempre estáveis. As redes de computadores se tornaram mais confiáveis, porém não estamos 100% livres de problemas de conectividade entre sistemas.
Redes de computadores são complexas, dinâmicas e frequentemente imprevisíveis. Diversas razões podem levar a uma falha de rede, como por exemplo:
- problemas de energia e/ou equipamentos,
- configurações erradas,
- quedas de zonas de disponibilidade e/ou datacenters inteiros,
- ataques de negação de serviço (DDoS).
A pergunta de um milhão de reais é: como construir uma arquitetura distribuída confiável se a própria arquitetura depende de um recurso não confiável com a rede de computadores?
A resposta para essa pergunta não é fácil e existem diversas ações para mitigar problemas de redes, indo desde soluções para hardwares até a forma como os softwares são construídos (e abordarei algumas dicas logo mais a frente neste artigo).
É fundamental estruturar a sua arquitetura aceitando o fato de que problemas de rede acontecerão a qualquer hora, afetando diferentes pontos do seu sistema, portanto, seus sistemas deverão ser por design tolerantes a falhas e ter redundância em elementos críticos para o seu funcionamento.
Somado a iniciativas de infraestrutura, toda a camada lógica da sua aplicação deve conseguir sobreviver a perda de conexões/mensagens devido a falhas na camada de rede.
2- A latência entre sistemas é nula.
Vamos imaginar que existam dois sistemas em um mesmo computador que precisem trocar mensagens entre si. Mesmo nesse cenário existirá alguma latência entre essa troca de mensagens, pois teremos latência de acesso a RAM, escalonamento de processos, IO em disco e outros.
Quando separamos esses sistemas em diferentes computadores pela rede, o custo da comunicação entre tais sistemas ira refletir todos os passos necessários dos pacotes serem transformados bem como transportados pelas diferentes camadas da sua arquitetura.
Latência significa atraso, isto é, o custo de tempo de um determinado evento desde o seu inicio até o seu fim. Por exemplo, no contexto de rede de computadores, a Cloudflare define latência como:
“A latência é o tempo que os dados levam para passar de um ponto de uma rede para outro”
fonte: https://www.cloudflare.com/pt-br/learning/performance/glossary/what-is-latency/
Imagine quantos saltos uma mensagem precisa levar para sair de um datacenter em São Paulo até Manaus, passando por uma dezena de equipamentos de telecom para chegar no computador de destino?

Uma característica essencial das redes de computadores, a latência é afetada principalmente pela distância entre dois pontos em uma rede. Mesmo em condições de rede perfeitas, os pacotes ainda assim atingirão limites físicos impostos pelo o meio de comunicação – por exemplo, quando falamos de equipamentos de fibra ótica, no melhor dos cenários seremos limitados a velocidade da luz.
A primeira dica para otimizar a latência é levar a fonte de dados para mais próximo do cliente, escolhendo datacenters geograficamente próximos aos seus usuários. Outras dicas são: o uso de caching, protocolos que acelerem o envio de pacotes (quando os tradeoffs permitem) e tunnings na sua aplicação para diminuir o tempo de processamento das mensagens. Vale lembrar que aplicações lentas também contribuem para a percepção de latência do seu usuário.
3 – A banda de rede é infinita.
Enquanto latência é a velocidade na qual dados vão do serviço A até o serviço B, largura de banda se refere a quantidade de dados que podem ser transmitidos dentro de uma janela de tempo.

Em 1994, quando L Peter Deutsch listou as falácias de rede, a largura de banda era algo muito mais limitada do que o que temos a disposição em qualquer cloud pública atualmente. Por exemplo, existem ofertas de máquinas na AWS (como a c5.18xlarge) que podem chegar até 25 Gigabites por segundo (ou 25Gbps). Para se ter idéia dessa dimensão, um streaming de vídeo 8K pode utilizar 200 Megabits por segundo.
Porém, embora tenhamos avanços significativos nesta área, ainda assim a rede continua sendo finita e custosa: quanto mais banda precisar, mais caro será a conta de infraestrutura.
Por exemplo, levantei a lista da largura de banda ofertada por tipo de instâncias EC2 na AWS:
$ aws ec2 describe-instance-types --filters "Name=instance-type,Values=c5.*" --query "InstanceTypes[].[InstanceType, NetworkInfo.NetworkPerformance]" --output table
-------------------------------------
| DescribeInstanceTypes |
+--------------+--------------------+
| c5.4xlarge | Up to 10 Gigabit |
| c5.xlarge | Up to 10 Gigabit |
| c5.12xlarge | 12 Gigabit |
| c5.24xlarge | 25 Gigabit |
| c5.9xlarge | 10 Gigabit |
| c5.2xlarge | Up to 10 Gigabit |
| c5.large | Up to 10 Gigabit |
| c5.metal | 25 Gigabit |
| c5.18xlarge | 25 Gigabit |
+--------------+--------------------+É preciso lembrar que com o passar do tempo, novos serviços e componentes serão acrescentados em nossa arquitetura. Assim, rapidamente chegamos a ter diversos itens bem como instâncias de banco de dados, soluções de monitoramento, logging, filas, gateways/proxies, servidores de arquivos, email, identidade de usuários e muitos outros. Isso é especialmente verdade em arquiteturas orientadas a microsserviços.
Quando começamos a atingir os limites da largura de banda, os seguintes sintomas começam a aparecer:
- Significativa perda de performance do sistema bem como instabilidades;
- Perda de pacotes de rede, ocasionado não apenas mensagens não entregues como também chegando constantemente fora de ordem)
- Atrasos por enfileiramento de mensagens; gargalos e congestão da rede;
Ações
- Transportar formatos de dados mais enxutos: podemos usar estratégias desde de mensagens com tamanho menor, compressão de mensagens (utilizando gzip no servidor http, por exemplo) ou usar tecnologias como MessagePack;
- Monitoramento: um monitor frequentemente ignorado por times mais incautos é o volume de dados trafegados. Reserve um espaço nos seus dashboards de monitoramento para o volume de bites trafegados e construa alertas para quanto atingir limites preocupantes;
- Protocolos otimizados para o uso de banda: protocolos como HTTP/2 (e HTTP/3) e mesmo websockets se beneficiam do uso da multiplexação de dados, técnica que permite combinar dados de diversas fontes e enviar pelo mesmo meio de comunicação;
4 – Redes são seguras.

“Segurança não é um produto, mas sim um processo. É mais do que implementar uma criptografia forte no sistema, é desenhar todo o sistema de tal modo que todas as medidas de segurança, incluíndo a criptografia, trabalhem juntos.”
Esta falsa verdade pode ser fatal para o negócio da sua empresa. Recentemente temos vistos inúmeros ataques a empresas gigantes de tecnologia brasileiras (e mundiais), sendo as falhas de segurança na rede um vetor de ataque bastante comum.
Uma rede de computadores pode ser atacada e comprometida de diversas formas: vulnerabilidades no sistema operacional ou bibliotecas usadas na sua aplicação, bugs, comunicação não-criptografadas entre componentes, vazamento de dados para sistemas não-autorizados, virus, ransomwares, cross-site scripting (XSS), ataques de negação de serviço (DDoS), e muitos outros.
Não devemos ignorar a possibilidade de ataques a nossos sistemas, vivendo como se isso fosse simplesmente uma remota possiblidade. A melhor forma de agir é entender que é uma questão de tempo: quando os sistemas forem atacados, o nível de segurança implementado em nossa arquitetura deverá ser capaz de limitar as perdas ao máximo possível.
Não sabe nem por onde começar? Uma boa recomendação é ler a lista OWASP’s Top 10, que aponta os riscos mais comuns que devemos prestar atenção em aplicações web.
5 – Sua topologia nunca irá mudar.
Topologia é o modelo adotado para conectar os diferentes dispositivos em uma rede. Em essência, é a estrutura física e lógica que dá formato e permite a comunicação de elementos em uma rede.
A única forma da topologia usada na sua aplicação não mudar é se você rodar seu software em seu computador, sem nenhuma dependência externa. No momento em que a sua aplicação passa a rodar em uma cloud pública (como AWS, GCP ou Azure), o controle da topologia não esta mais em suas mãos.
É extremamente comum provedores de cloud fazerem atualizações e upgrades em diversos componentes de infraestrutura, adicionarem novos componentes ou removerem antigos – e nem sempre você será avisado com antecedência das janelas de procedimento.
Ao conceber a arquitetura da sua aplicação distribuída, você não pode depender de uma topologia imutável para que a execução da sua solução seja satisfatória para o seu usuário final.
6 – Há somente um administrador.
No passado, uma única pessoa (ou um time pequeno) era responsável pela administração do ambiente de rede, com operações agendadas para acontecerem, até então, de maneira sequencial.
Com o avanço dos ambientes em nuvem e a evolução das práticas de Devops, tivemos uma mudança brusca em como a infraestrutura é administrada.
Aplicações cloud-native modernas dependem de um grande número de serviços externos. Portanto, a manutenção destes sistemas exigem uma miríade de pessoas e procedimentos para correção, atualização e otimização dos componentes (hardware e software).

Embora na teoria todas essas operações devam ser transparentes para a sua aplicação, o mundo real nem sempre é tão benevolente, exigindo que a sua solução consiga operar parcialmente caso alguma dessas dependências apresente problemas.
Algumas dicas importantes para facilitar a administração do seu ambiente é:
- Faça com que a investigação de problemas seja simples: visibilidade da saúde dos itens da sua arquitetura é crucial para identificar problemas quando eles ocorrem. Por exemplo, podemos focar em logs, métricas, tracing e exceções com mensagens claras.
- Desacople componentes: sempre que possível, garanta que o seu sistema consiga se relacionar de maneira desacoplada de suas dependências. Assim, quando alguma janela de manutenção externa acontecer, a sua arquitetura consiguirá mitigar os efeitos repassados para os seus usuários.
7 – Custos de transporte de dados é zero.
Servidores, switches, balanceadores de carga, proxies, firewalls, segurança e pessoas tecnicamente capacitadas são apenas alguns dos custos financeiros que envolve manter um datacenter funcionando. E quanto maior a rede e a oferta de serviços, certamente maiores serão os custos financeiros envolvidos.
Ao rodar a sua solução em um datacenter, seja ele público ou privado, todos esses elementos precisam fazer parte do calculo final de custo que a sua aplicação tem.
Em adição aos custos acima, podemos adicionar o tempo, processamento e energia gastos para cada transação feita pelos seus usuários em seus sistemas. E para que seus usuários consigam realizar suas tarefas, projetamos a arquitetura dos nossos sistemas para ser altamente disponível, consistente e tolerante a falhas.
Não é de se surpreender que muitas empresas prefiram usar soluções de infraestrutura como serviço, conhecidas como IaaS – frequentemente elas são mais estáveis, simples e eficiente em custos, mas possuem um modelo de negócio que vai te cobrar pelo uso de banda, processamento e armazenamento de dados.

Para economizar na conta, tente sempre otimizar o transporte de mensagens, evitando formatos de extremamente verbosos (como os baseados em XML por exemplo), optando por usar soluções de serialização/deserialização mais leves, como JSON, MessagePack e Protocol buffers.
8 – Rede é um ambiente homogêneo.
Redes de computadores são em sua esmagadora maioria diferentes entre si, apresentando diferentes topologias, equipamentos, meios de transporte, etc.
Sistemas distribuídos frequentemente precisarão integrar com diferentes tipos de dispositivos, sistemas operacionais, navegadores e protocolos. Inegavelmente, a interoperabilidade é uma característica fundamental quando pensamos em sistemas modernos, garantindo que todos os componentes em um sistema consiga conversar entre si, indiferente das características internas de cada um.

Devemos portanto seguir protocolos de comunicação abertos sempre que possível, usados pela maior parte do mercado, evitando ao máximo as opções proprietárias. Só para exemplificar, temos o próprio HTTP, ServerSend Events e WebSockets.
Como medir a disponibilidade de um sistema distribuído?
Disponibilidade, no contexto que estamos estudando, é o quanto o sistema continua operacional para executar uma determinada tarefa que lhe é demandada.
Existem duas formas principais de lermos a disponibilidade de um sistema: a mais comum é baseada na dimensão de tempo – e é a que usaremos aqui. A outra forma é quantidade de execuções do sistema ou parte dele (como por exemplo, o número de requests em uma rota específica).
Como calcular a disponibilidade
O calculo de disponibilidade usando a dimensão de tempo é feito da seguinte forma:

Por exemplo, se queremos calcular a disponibilidade de 90% de tempo em um ano (e um ano tem 8.760 horas), a conta seria: 7.884 horas (que é o tempo disponível da aplicação) dividido por 8.760 horas (tempo total em um ano), resultando em 876 horas (ou 36,5 dias).
Em outras palavras: para a sua aplicação ficar disponível pelo menos 90% do ano, ela não pode ficar mais do que 876 horas fora do ar.
Segue abaixo o calculo para outros níveis de disponibilidade (também conhecido como classes dos “9”):
| Disponibilidade | Classe dos 9 | Tempo máximo de indisponibilidade por ano |
|---|---|---|
| 90% | um “9” | 36,5 dias |
| 99% | dois “9” | 3,6 dias |
| 99.9% | três “9” | 8,7 horas |
| 99.99% | quatro “9” | 52,6 minutos |
| 99.999% | cinco “9” | 5.2 minutos |
O que é alta disponibilidade
Um objetivo comum aos sistemas distribuídos é a alta disponibilidade (do inglês high availability, ou simplesmente HA) – que é a capacidade de um sistema funcionar continuamente durante um longo período de tempo. Quando falamos de HA, procuramos fazer com que o sistema satisfaça um nível de performance previamente acordado, geralmente respeitando alguma classe dos 9 acima.
O Santo Graal do mundo da alta disponibilidade é atingir a difícil meta dos “cinco noves da disponibilidade”, com o propósito de estar disponível 99.999% do tempo.
Sistemas com alta disponibilidade são usados em lugares em que sua execução é crítica para o negócio. Quanto maior a disponibilidade de um sistema, maior o custo total para mantê-lo, por isso é importante que os desenvolvedores tenham um acordo claro com a área de negócio sobre qual é disponibilidade esperada, pois isso terá um forte impacto no custo ao definir a arquitetura do sistema.
Por que não 100% de disponibilidade?
Uma das primeiras perguntas que surgem quando falamos de disponibilidade é por que a meta da alta disponibilidade não é 100%? Simples: é impossível garantir que você terá 100% de operação dos seus sistemas durante todo o tempo.
O primeiro motivo de não termos 100% de garantias é a própria infraestrutura de base que usamos. Basta analisar o contrato dos maiores cloud providers do mercado que você encontrará garantias próximas a 100%, mas nunca a sua integralidade. Todos os componentes de infra precisarão de manutenção, atualização ou trocas, e portanto, por mais cuidado que se tenha, alguma indisponibilidade poderá ocorrer.
O segundo motivo é o custo. A cada novo “9” é que adicionado na conta dos “99%”, maiores ficam os custos de infra e operação, ao ponto que em algum momento a conta de retorno vs. investimento não fechará. Assim, nesse momento será mais barato lidar com as consequências da indisponibilidade do que investir na prevenção.
O terceiro motivo são os “atos de Deus” (do inglês “acts of God“): maiores problemas na infraestrutura que você não tem controle e mesmo o seu cloud provider tem dificuldade de se proteger dos impactos, tais como inundações, terremotos, furacões, pandemias ou outros desastres naturais.
Patterns para ambientes distribuídos
Com o aparecimento dos desafios em ambientes distribuídos, em especial na arquitetura baseada em microsserviços na cloud, a arquitetura de software também evoluiu trazendo respostas aos problemas mais comuns.
Conhecidos por serem boas práticas que permitem um maior desacoplamento entre sistemas, maior independência entre deploys e focado em uma melhoria de testabilidade (e manutenção), as técnicas abaixo trazem soluções e novos pontos as serem considerados.
Minha intenção aqui é catalogar as abordagens mais comuns e portanto a lista abaixo não tem o objetivo de ser um guia exaustivo sobre o tema. Sites como microservices.io e a documentação sobre Cloud Design Patterns da Azure podem servir de complemento aos itens apresentados. Vamos lá!
Timeouts
O padrão mais simples de implementar e com benefícios claros: nossos sistemas não podem ficar esperando infinitamente uma resposta de serviços externos a aplicação. Toda vez que um processo precisa aguardar uma resposta, como por exemplo em uma chamada HTTP ou query no banco, recursos são alocados e só são liberados quando há um resposta ou algum componente decida cancelar a operação devido a um período de tempo de espera ter chegado ao limite.
Timeout é um limite de tempo máximo que um componente pode esperar para a conclusão de um determinado evento.
Com um timeout definido, podemos diminuir a quantidade de recursos bloqueados na nossa aplicação e adiantarmos o uso de algum comportamento de contorno em caso de falha nas dependências.
// Exemplo de configuração de timeout
// em um client http Go
var netClient = &http.Client{
// Configurando 2 segundos de timeout
Timeout: time.Second * 2,
}
// executando a chamada com o timeout configurado
response, err := netClient.Get("https://servicoexterno.com")
// checando o erro caso haja
if err != nil {
if os.IsTimeout(err) {
// Aqui você sabe que houve um erro de timeout
return
}
// Aqui você sabe que houve um erro de outro tipo
return
}🔥 Pontos de atenção ao usar Timeouts 🔥
- Timeouts não resolvem problemas recorrentes de conectividade. É importante monitorar a latência dos seus componentes para entender qual a frequência em que lentidões nas suas dependências são notadas.
- Diferentes componentes na sua arquitetura podem ter diferentes timeouts configurados, o que traz uma maior complexidade na hora de identificar problemas. Criar uma visão coesa em seu monitoramento sobre todos os timeouts que ocorreram é fundamental para entender qual camada da sua arquitetura esta decidindo cancelar requisições.
Retry
Estratégia fundamental para lidar com problemas transientes, a retentativa automática é o caminho natural para evitarmos uma falha definitiva durante alguma ação importante do nosso sistema.
Retries possibilitam que uma aplicação possa retentar uma operação que falhou, resolvendo de maneira transparente problemas transientes ao tentar se conectar a um serviço ou recurso na rede.
Os três estados comuns da sua aplicação ao implementar uma estratégia de retry serão:
 |  |  |
| A operação é cancelada | A operação é retentada imediatamente | A operação é retentada após espera (o intervalo pode ser fixo ou variável) |
| A falha não é temporária e dificilmente será resolvida em uma retentativa. Ex: Senha errada em uma tentativa de autenticação de um usuário. | Falhas raras, fruto de condições não usuários. Ex: Erros de pacotes de rede corrompidos. | Caso mais comum, geralmente indicado para problemas causados por dependências externas que apresentam falhas temporárias. Ex: API externa sofrendo devido carga próxima ao seu limite de operação. |
🔥 Pontos de atenção ao usar Retries 🔥
- Para operações não criticas, o uso de retries pode causar custos que não valham a pena. É melhor aceitar falhar na primeira tentativa, do que fazer com que todos os sistemas, em todas as operações, retentem diversas vezes – principalmente durante momentos de problemas mais graves que dificilmente se resolverão durante as retentativas.
- Ao implementar alguma lógica de retry, é importante que a dependência que receberá as múltiplas chamadas não sofra com a repetição das operações. Imagine, por exemplo, que uma API de pagamento efetue diversas cobranças repetidas para um usuário devido a uma lógica de retry com algum bug.
Como a lógica de retry pode fazer com que uma mesma operação seja executada mais de uma vez, é importante que a sua arquitetura tenha alguma estratégia de idempotência implementada.
- Caso decida implementar alguma lógica de retry em uma operação transacional, leve em consideração o custo do rollback durante as retentativas. Pode ser que você só decida fazer o rollback caso a ultima retentativa apresente falha, evitando o custo de desfazer a operação a cada nova tentativa.
- Não faça retentativas em falhas que são decorrentes de situações permanentes, como por exemplo, criticas de regras de negócio implementadas em uma aplicação externa. Não importa quantas vezes sua aplicação retentará, as validações no código da aplicação continuarão invalidando a operação.
- Não use retries para resolver um problema de escalabilidade. Se a sua aplicação frequentemente precisa retentar suas operações devido a problemas de lentidão em suas dependências, isso é um sinal de que a sua dependência necessita escalar.
Circuit Breaker

Esta é uma técnica que visa aumentar a tolerância a falhas em arquiteturas distribuídas, possibilitando o alívio de uso em uma dependência que apresente falhas por estar sobrecarregada das inúmeras chamadas feitas pelos seus consumidores.
A técnica de Circuit Breaker é simples: monitorar a quantidade de falhas em um ponto especifico da sua aplicação e alterar o comportamento da mesma caso o volume de erros chegue a um limite configurado.
Uma vez que o limite de erros seja atingido, o circuito passar a impedir que novas chamadas sejam feitas, retornando imediatamente um erro e impedido que novas execuções sejam feitas até que o volume de erros diminua.
Os circuitos são funções ou classes que encapsulam o código monitorado (como uma chamada a algum recurso externo como banco de dados, caches, APIs, etc) e mantém internamente contadores de falhas e sucesso dentro de alguma janela de tempo ou quantidade de execuções.
Transições comuns
Para conseguir controlar os possíveis estados do seu monitoramento, eles contam com uma máquina de estados que geralmente transita entre os três estados: Aberto (open), Fechado (closed) ou Meio-Aberto (half-open).

- Closed: quando tudo esta funcionando normalmente, o circuito permanece nesse estado e todas as chamadas ocorrem normalmente. Se o número de erros atingir um limite pré-configurado (por exemplo, 5% de erros nos últimos 10 minutos), o estado do circuito muda para Open.
- Open: nesse estado, o circuito não executará a o código que apresenta erros e retornará um erro padrão (ou assumir algum comportamento de contorno, como retornar um valor padrão ou cacheado)
- Half Open: após um período, o estado do circuito é alterado para esse estado. Nele, são realizadas retentativas de execução do trecho de código coberto pelo circuito, testando assim o reestabelecimento da dependência com problemas. Dependendo do sucesso ou falha, o circuito muda seu estado novamente para Closed ou Open.
🔥 Pontos de atenção ao usar Circuit Breakers 🔥
- Dependendo do tipo de dependência que você esta protegendo com seu circuito pode ser difícil realizar testes que estressem todos os estados existentes.
- Em um um ambiente com diversos sistemas conversando entre si (como as arquiteturas baseadas em microsserviços), o ideal é que exista alguma solução a nível de infraestrutura (como o Istio para ambientes Kubernetes).
Do contrário, todas os sistemas terão que implementar localmente alguma estratégia – aumentando o custo de manutenção e possivelmente introduzindo algum nível de duplicação de código.
- É importante que o estado dos circuit breakers estejam incluídos nos dashboards de monitoramento da sua arquitetura, e se necessário, existam alarmes para quando algum circuit breaker importante mude de estado para Aberto.
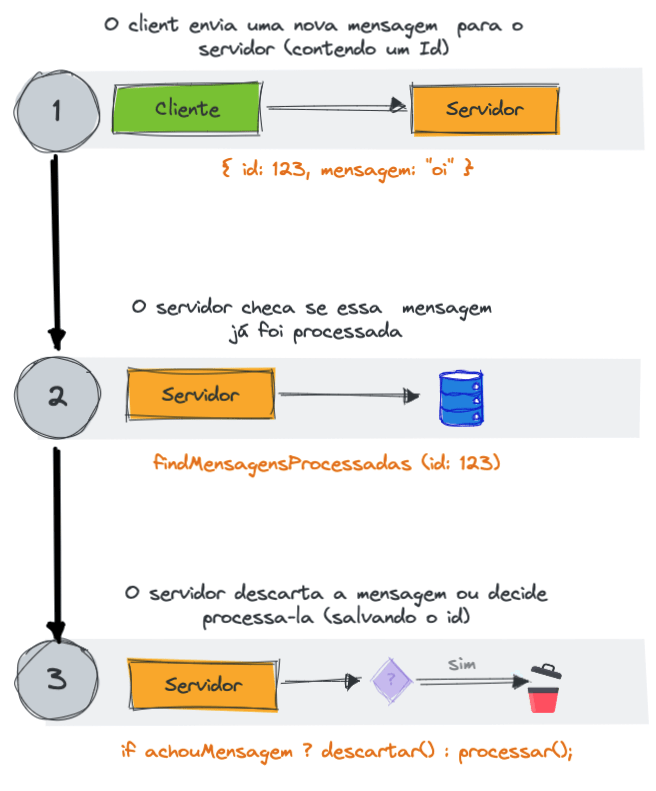
Clientes Idempotentes
Este padrão é fundamental para evitarmos problemas causados pelo o reenvio de mensagens – é através dele que podemos impedir que uma determinada mensagem seja processada mais de uma vez.
Quando pensamos em padrões de entrega de mensagens, existem três possibilidades:

É bastante comum em cenários de instabilidade que sistemas ou até mesmo usuários decidam retentar alguma operação sem ter garantias de que a primeira tentativa foi completamente descartada.
Por exemplo, vamos imaginar o fluxo de pagamento em um e-commerce sendo feito através de um celular sofrendo com lentidão da rede de dados – um cenário bastante comum no Brasil. Após um longo período de espera por uma resposta HTTP, o navegador do celular decide cancelar o request justamente no final da operação de pagamento. E agora, o pagamento foi ou não realizado?
O padrão de clientes idempotentes é muito útil nesses casos. Sua implementação é relativamente simples, bastando adicionar alguma camada na sua arquitetura armazenar um identificador das mensagens já processadas, respeitando uma janela de tempo que faça sentido em seu contexto.
Para tal, é necessário também que o produtor da mensagem crie um identificador único para a mesma, sendo responsável por manter esse mesmo ID em todos os reenvios da mesma mensagem.
🔥 Pontos de atenção ao usar Clientes Idempotentes 🔥
- Introdução de maior complexidade no código do seu projeto: agora existe um contrato que deve ser seguido entre o servidor e todas as aplicações clientes.
- Um maior custo de infra, uma vez que precisaremos de uma camada de persistência para o histórico de mensagens processadas – e esse item rapidamente pode se tornar o gargalo em momentos de pico, necessitando de uma estratégia de escalabilidade rápida, caso necessário.
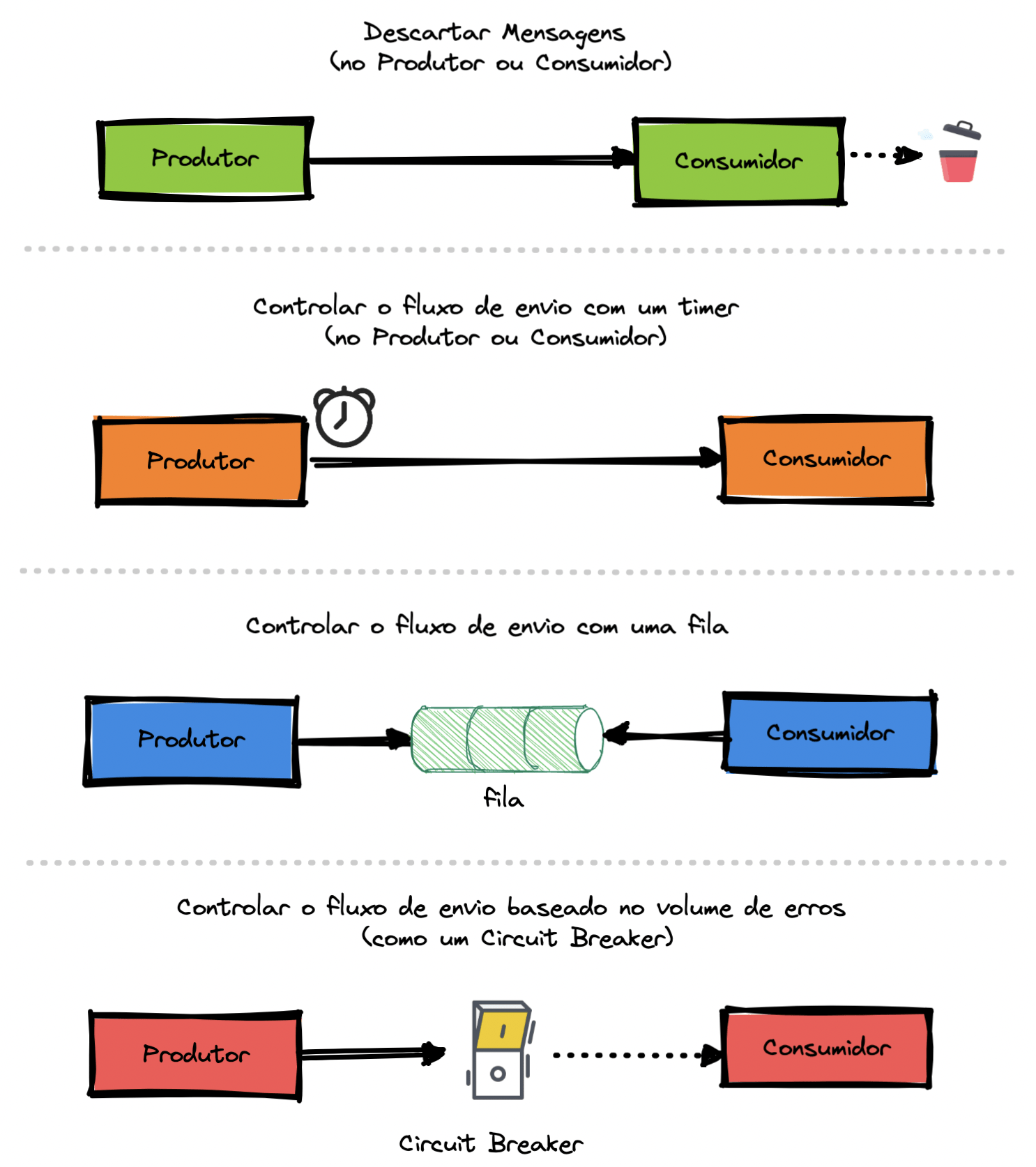
Rate Limiter
A estratégia com Rate Limit é baseada no fato de que os recursos possuem uma capacidade limitada de atendimento e que portanto, é necessário existir o controle na quantidade de operações que um sistema pode criar, enviar ou consumir de um determinado recurso.
Os benefícios dessa estratégia são:
- Evitar a exaustão de serviços
- Limitar a propagação de erros em cascata
- Sobreviver a ataques de negação de serviço
- Economizar o consumo de recursos
Existem algumas formas mais comuns de se utilizar esse pattern. São elas:
🔥 Pontos de atenção ao usar Rate Limit: 🔥
- Em caso de alta demanda dos sistemas fruto de um pico de acessos, os componentes responsáveis por controlar o rate limit podem se tornar pontos de gargalo na sua arquitetura.
- Em um ambiente com diversos times, pode haver diferentes implementações e configurações de rate limiting.
- Quando se usa componentes específicos na sua arquitetura para controlar o rate limit dos sistemas (com o proxies ou gateways), você é obrigado a fragmentar configurações que são do domínio da sua aplicação por diferentes itens na sua arquitetura.
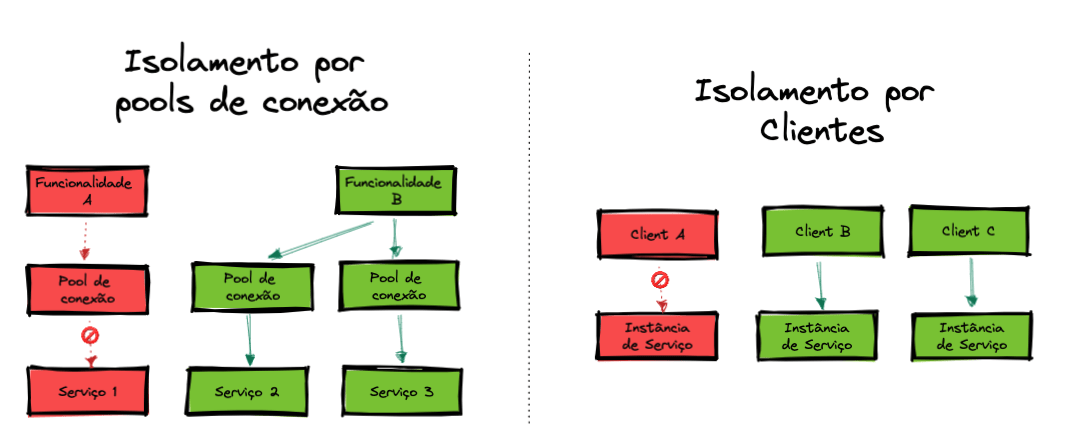
Bulkhead
Apesar do nome peculiar, o modelo de arquitetura bulkhead visa em primeiro lugar isolar elementos (ou dependências) de uma aplicação em pools de maneira que se uma parte falhar, outras continuem funcionando. Assim, dessa forma melhoramos o isolamento de recursos, a proteção contra falhas em cascata e podemos priorizar recursos para funções críticas do nosso sistema.
O nome “bulkhead” (podendo ser traduzido como divisória) é inspirado nas divisões internas do casco de um navio: caso haja entrada de água, a mesma é isolada em segmentos, evitando então a inundação completa do barco:

Para implementar o padrão, precisamos garantir que os nossos serviços consigam funcionar de maneira isolada, fazendo com que a falha de uma dependência não afete outra. Técnicas como o padrão da responsabilidade única, comunicação assíncrona e isolamento de pools de conexão por responsabilidade.
Podemos categorizar duas formas mais comuns de implementarmos o padrão bulkhead. São elas:
🔥 Pontos de atenção ao usar Bulkheads 🔥
- Introdução de maior complexidade no código do seu projeto
- Uma menor otimização de recursos, uma vez que esta técnica disponibiliza recursos de maneira segmentada, impedindo um melhor reaproveitamento entre componentes.
Conclusão e recomendação de leitura
Em um tema tão extenso quando este, a tarefa mais difícil é definir o que não abordar. Deixei alguns pontos importantes fora desse post que serão temas de novas publicações.
Para aqueles que desejam continuar os estudos, deixo abaixo uma sugestão de material complementar ao post. Te convido a usar a área de comentários para continuarmos o assunto 😊. Não deixe de compartilhar suas experiências e estudos sobre o tema!
- Introduction to Distributed Systems, Google
- Cloud Design Patterns, Microsoft
- Microservices Architecture, Microservices.io
- A Thorough Introduction to Distributed Systems, Stanislav Kozlovski
- Distributed Systems: Fault Tolerance, Professor Jussi Kangasharju
- Transient Fault Handling, Microsoft
- Distributed Systems for Fun and Profit, Mikito Takada
- What is High Availability?, Erika Heidi
- High availability versus fault tolerance, IBM
- Fault Tolerance in Distributed Systems, Sumit Jain
- Fault Tolerance: Reliable Systems from Unreliable Components, Jerome H. Saltzer and M. Frans Kaashoek
- Distributed Systems: Fault Tolerance, Professor Jussi Kangasharju
- Fault Tolerance, Paul Krzyzanowski
- Sistemas Distribuídos: Conceitos e Definições, por Marcelo M. Gonçalves