Cgroups são uma funcionalidade do kernel do Linux que permite aos administradores recursos de sistema
Compartilhar
Pedro Mendes Publicado há 8 months atrás.
Cgroups, também conhecidos como Control Groups, são uma funcionalidade do kernel do Linux que permite aos administradores do sistema limitar, isolar e priorizar recursos de sistema, como CPU, memória e I/O. Essa tecnologia é particularmente útil em ambientes de computação em nuvem, onde muitos usuários compartilham os mesmos recursos físicos.
Com Cgroups, os administradores podem criar grupos de processos e definir limites de recursos para cada grupo. Por exemplo, eles podem limitar a quantidade de CPU que um grupo pode usar, ou garantir que um grupo tenha prioridade sobre outros grupos quando se trata de acesso ao disco. Essa abordagem permite que os administradores gerenciem melhor os recursos do sistema e evitem que um único processo ou usuário monopolize os recursos.
Embora Cgroups tenham sido originalmente desenvolvidos para uso em servidores, eles também são úteis em sistemas de desktop e laptop. Por exemplo, você pode usar Cgroups para limitar a quantidade de CPU que um processo específico pode usar, ou para garantir que um processo de backup não interfira na capacidade de resposta do sistema durante o uso normal. Em suma, Cgroups oferece aos administradores e usuários do Linux uma maneira poderosa de gerenciar recursos de sistema e garantir que o sistema operacional opere de maneira eficiente e confiável.
Conceito de Cgroups
Cgroups, ou Control Groups, é um recurso do kernel Linux que permite limitar, isolar e controlar o uso de recursos de um conjunto de processos. Com o Cgroups, é possível definir limites de CPU, memória, I/O de disco e rede para grupos de processos, permitindo que os recursos do sistema sejam alocados de forma mais eficiente.
O Cgroups funciona agrupando processos em hierarquias, onde cada grupo pode ter limites de recursos definidos e ser controlado separadamente. Isso permite que os recursos sejam alocados de forma justa entre diferentes grupos de processos, evitando que um grupo monopolize os recursos do sistema.
Além disso, o Cgroups pode ser usado para limitar o acesso de um grupo de processos a determinados dispositivos ou recursos do sistema, o que é útil para garantir a segurança e a estabilidade do sistema.
Em resumo, o Cgroups é uma ferramenta poderosa para controlar o uso de recursos de um conjunto de processos, permitindo que o sistema seja alocado de forma mais eficiente e garantindo a segurança e a estabilidade do sistema.
Funcionalidades do Cgroups
O Cgroups, ou Control Groups, é uma ferramenta poderosa de gerenciamento de recursos do kernel Linux. Ele permite que os usuários criem grupos de processos e atribuam limites de recursos a esses grupos, como CPU, memória e largura de banda.
Gerenciamento de Recursos
Uma das principais funcionalidades do Cgroups é o gerenciamento de recursos. Com ele, os usuários podem limitar a quantidade de recursos que um grupo de processos pode usar. Isso é especialmente útil em ambientes de servidor, onde é importante garantir que os recursos sejam distribuídos de forma justa entre os processos.
Isolamento de Processos
Outra funcionalidade importante do Cgroups é o isolamento de processos. Com ele, os usuários podem isolar processos em grupos separados, impedindo que um processo afete o desempenho de outros processos no sistema. Isso é especialmente útil em ambientes de servidor, onde é importante garantir que um processo malicioso não possa afetar outros processos no sistema.
Priorização de Processos
O Cgroups também permite que os usuários priorizem processos em relação a outros processos no sistema. Isso é especialmente útil em ambientes de servidor, onde é importante garantir que processos críticos tenham prioridade sobre outros processos menos importantes.
Em resumo, o Cgroups é uma ferramenta poderosa de gerenciamento de recursos do kernel Linux, que permite que os usuários criem grupos de processos e atribuam limites de recursos a esses grupos. Ele também permite o isolamento de processos e a priorização de processos, tornando-o extremamente útil em ambientes de servidor.
Implementação de Cgroups
O Cgroups é uma ferramenta que permite o gerenciamento de recursos do sistema operacional Linux. Com ele, é possível limitar o uso de CPU, memória RAM, I/O e outros recursos do sistema para um grupo específico de processos. Nesta seção, serão abordados os passos necessários para criar e configurar Cgroups.
Criação de Cgroups
Para criar um novo Cgroup, é necessário acessar o diretório /sys/fs/cgroup e criar um novo diretório com o nome do grupo desejado. Por exemplo, para criar um Cgroup chamado “grupo1”, basta executar o seguinte comando:
# mkdir /sys/fs/cgroup/grupo1
É possível criar subgrupos dentro de um Cgroup existente, basta criar um novo diretório dentro do diretório do Cgroup pai. Por exemplo, para criar um subgrupo chamado “subgrupo1” dentro do grupo “grupo1”, basta executar o seguinte comando:
# mkdir /sys/fs/cgroup/grupo1/subgrupo1
Configuração de Cgroups
Após criar um Cgroup, é possível configurá-lo para limitar o uso de recursos do sistema. Para isso, é necessário editar o arquivo de configuração do Cgroup, localizado em /sys/fs/cgroup/<nome_do_cgroup>/.
Por exemplo, para limitar o uso de CPU do grupo “grupo1” para 50%, basta editar o arquivo cpu.shares e definir o valor para 512 (o valor padrão é 1024):
# echo 512 > /sys/fs/cgroup/cpu/grupo1/cpu.shares
Além disso, é possível limitar o uso de memória RAM, I/O, entre outros recursos do sistema, editando os arquivos de configuração correspondentes.
Com a configuração de Cgroups, é possível garantir que um grupo específico de processos não consuma todos os recursos do sistema, garantindo assim um melhor desempenho e estabilidade do sistema operacional Linux.
Usos Práticos do Cgroups
Containerização
O Cgroups é uma ferramenta muito útil para a containerização de aplicações. Com ele, é possível limitar a quantidade de recursos que uma aplicação pode utilizar, como CPU, memória RAM e espaço em disco, o que ajuda a garantir que outras aplicações em execução no mesmo sistema não sejam prejudicadas.
Além disso, o Cgroups permite a criação de hierarquias de controle de recursos, o que é especialmente útil em ambientes de containerização. Com isso, é possível garantir que uma aplicação não utilize mais recursos do que o necessário e, ao mesmo tempo, garantir que outras aplicações tenham acesso aos recursos que precisam.
Balanceamento de Carga
Outra aplicação prática do Cgroups é o balanceamento de carga. Com ele, é possível distribuir a carga de trabalho entre diferentes processos ou sistemas, garantindo que nenhum deles fique sobrecarregado.
O Cgroups permite a criação de grupos de processos, que podem ser distribuídos entre diferentes servidores ou máquinas virtuais. Com isso, é possível garantir que cada grupo tenha acesso aos recursos necessários para executar suas tarefas, sem sobrecarregar o sistema como um todo.
Além disso, o Cgroups permite a definição de prioridades de execução para cada grupo, o que ajuda a garantir que os processos mais importantes sejam executados primeiro, sem prejudicar os demais.
Em resumo, o Cgroups é uma ferramenta poderosa e flexível, que pode ser utilizada de diversas maneiras para melhorar o desempenho e a eficiência de sistemas e aplicações.
Limitações e Desafios do Cgroups
O Cgroups é uma ferramenta poderosa para gerenciamento de recursos em sistemas Linux, mas ainda apresenta algumas limitações e desafios que precisam ser considerados.
Limitações
Limitações de precisão: O Cgroups não é capaz de garantir precisão absoluta na alocação de recursos, especialmente em ambientes de múltiplos usuários ou processos. Isso pode levar a situações em que um processo pode consumir mais recursos do que o esperado, prejudicando outros processos ou usuários.
Limitações de escalabilidade: O Cgroups pode enfrentar problemas de escalabilidade em sistemas com grande número de processos ou grupos de controle. Isso pode levar a atrasos no gerenciamento de recursos e perda de desempenho.
Limitações de compatibilidade: O Cgroups pode não ser compatível com todas as versões do kernel Linux ou com todos os sistemas de arquivos. Isso pode limitar a sua utilização em alguns ambientes.
Desafios
Desafios de configuração: O Cgroups pode ser desafiador de configurar, especialmente para usuários iniciantes ou sem conhecimento avançado de sistemas Linux. Isso pode levar a erros de configuração e problemas de desempenho.
Desafios de monitoramento: O Cgroups não fornece uma ferramenta de monitoramento integrada, o que pode tornar difícil a identificação de problemas de desempenho ou consumo de recursos.
Desafios de compatibilidade: O Cgroups pode não ser compatível com todas as aplicações ou ferramentas de gerenciamento de sistemas, o que pode limitar a sua utilização em alguns ambientes.
Apesar dessas limitações e desafios, o Cgroups ainda é uma ferramenta valiosa para gerenciamento de recursos em sistemas Linux, especialmente em ambientes de alta demanda de recursos.
Futuro do Cgroups
Cgroups é uma tecnologia de gerenciamento de recursos de sistema que tem sido amplamente adotada em ambientes de servidor para limitar o uso de recursos de CPU, memória e disco. O futuro do Cgroups parece promissor, com várias melhorias sendo planejadas para torná-lo ainda mais poderoso e flexível.
Uma das principais melhorias planejadas é a adição de suporte para limites de rede. Isso permitirá que os administradores de sistema limitem o uso de largura de banda de rede para processos específicos, o que é especialmente útil em ambientes de servidor onde a largura de banda de rede é um recurso limitado.
Outra melhoria planejada é a adição de suporte para limites de E/S. Isso permitirá que os administradores de sistema limitem a taxa de E/S para processos específicos, o que pode ajudar a prevenir a degradação do desempenho do sistema devido a processos intensivos em E/S.
Além disso, há planos para melhorar a integração do Cgroups com outras tecnologias de virtualização, como o Docker e o Kubernetes. Isso tornará mais fácil para os administradores de sistema gerenciar recursos de sistema em contêineres e ambientes de orquestração de contêineres.
Em resumo, o futuro do Cgroups parece brilhante, com várias melhorias planejadas para torná-lo ainda mais poderoso e flexível. Os administradores de sistema podem esperar continuar a usar o Cgroups para gerenciar recursos de sistema em ambientes de servidor e contêineres.
Linux Containers (LXC) são uma tecnologia de virtualização que permite a execução de múltiplos sistemas operacionais em um único host.
Compartilhar
Pedro Mendes Publicado há 8 months atrás.
Linux Containers (LXC) são uma tecnologia de virtualização que permite a execução de múltiplos sistemas operacionais em um único host. Essa tecnologia é baseada no kernel do Linux e oferece uma alternativa leve e rápida para a virtualização tradicional baseada em hipervisor. LXC é uma solução ideal para a criação de ambientes isolados para desenvolvimento, testes e produção.
Os containers LXC são criados a partir de imagens base, que contêm um sistema operacional completo e todos os pacotes necessários para executar aplicativos. Cada container é isolado do host e de outros containers, o que significa que ele tem seu próprio sistema de arquivos, processos e rede. Essa abordagem de isolamento garante que os containers não interferem uns com os outros e que o host é protegido contra possíveis ameaças.
Os containers LXC são uma tecnologia madura e amplamente utilizada em ambientes de produção. Eles oferecem uma maneira eficiente e segura de executar aplicativos em um único host, o que reduz o custo e a complexidade da infraestrutura de TI. Além disso, a facilidade de criação e gerenciamento de containers torna essa tecnologia uma escolha popular para desenvolvedores e administradores de sistemas.
O que são Contêineres Linux (LXC)
Os contêineres Linux (LXC) são uma tecnologia de virtualização leve que permite a execução de múltiplos sistemas operacionais isolados em um único host. Os contêineres são uma alternativa aos sistemas de virtualização tradicionais, como as máquinas virtuais (VMs), que exigem recursos significativos para a virtualização.
Os contêineres LXC são criados a partir de imagens de sistema operacional, que contêm todo o software necessário para o sistema operacional funcionar. Cada contêiner é isolado do host e de outros contêineres, permitindo que diferentes sistemas operacionais e aplicativos sejam executados em um único host sem interferir uns com os outros.
Os contêineres LXC são gerenciados por meio de ferramentas de linha de comando, que permitem a criação, inicialização, parada e exclusão de contêineres. Além disso, os contêineres podem ser configurados para compartilhar recursos com o host, como o sistema de arquivos, a rede e os dispositivos.
Os contêineres LXC são amplamente utilizados em ambientes de desenvolvimento e produção, pois permitem a implantação rápida e fácil de aplicativos em diferentes sistemas operacionais e plataformas. Eles também são uma opção popular para a criação de ambientes de teste e para a execução de aplicativos em nuvem.
Como funcionam os Contêineres Linux
Os Contêineres Linux (LXC) são uma tecnologia de virtualização que permite a criação de ambientes isolados dentro de um sistema operacional host. Eles são uma forma de virtualização leve que permite a execução de aplicativos em um ambiente isolado sem a necessidade de uma máquina virtual completa.
Os contêineres Linux funcionam usando recursos do kernel do Linux, como namespaces e cgroups, para isolar os processos e recursos do sistema. Os namespaces permitem que cada contêiner tenha sua própria visão do sistema, incluindo o sistema de arquivos, processos, usuários e redes. Os cgroups permitem que o sistema operacional limite o uso de recursos do sistema, como CPU, memória e armazenamento, para cada contêiner.
Os contêineres Linux são criados a partir de imagens, que contêm todo o software necessário para executar um aplicativo em um ambiente isolado. Essas imagens podem ser criadas manualmente ou baixadas de um registro de imagens, como o Docker Hub. Os contêineres são iniciados a partir dessas imagens e podem ser configurados para se comunicar com outros contêineres ou com o host.
Os contêineres Linux são amplamente utilizados em ambientes de desenvolvimento e produção para fornecer uma maneira fácil e eficiente de implantar aplicativos. Eles permitem que os desenvolvedores criem ambientes de desenvolvimento consistentes e replicáveis, enquanto os administradores do sistema podem implantar aplicativos rapidamente e com segurança.
Vantagens dos Contêineres Linux
Os contêineres Linux (LXC) oferecem uma série de vantagens em relação a outras tecnologias de virtualização, como a virtualização completa do sistema operacional (VMs). Algumas dessas vantagens incluem:
Eficiência de Recursos
Os contêineres Linux são muito mais leves do que as VMs, o que significa que eles usam menos recursos do sistema, como memória e espaço em disco. Isso os torna ideais para ambientes em que a eficiência de recursos é uma prioridade, como em servidores de produção e em ambientes de nuvem.
Isolamento de Processos
Os contêineres Linux também oferecem um alto grau de isolamento de processos. Cada contêiner é executado em seu próprio espaço de usuário e de rede, o que significa que os processos em um contêiner não podem interferir nos processos em outros contêineres ou no sistema hospedeiro. Isso torna os contêineres Linux ideais para a execução de aplicativos em ambientes de produção, onde a segurança e o isolamento são críticos.
Portabilidade
Os contêineres Linux são altamente portáteis e podem ser executados em praticamente qualquer sistema Linux que tenha suporte para contêineres. Isso torna os contêineres Linux ideais para ambientes em que a portabilidade é uma prioridade, como em ambientes de desenvolvimento e teste. Além disso, os contêineres Linux podem ser facilmente movidos entre diferentes sistemas Linux sem a necessidade de reconfiguração ou ajuste.
Em resumo, os contêineres Linux oferecem uma solução leve e eficiente para a virtualização de aplicativos e serviços em ambientes de produção e desenvolvimento. Com sua eficiência de recursos, isolamento de processos e portabilidade, os contêineres Linux são uma escolha popular para empresas e desenvolvedores que buscam uma solução de virtualização flexível e escalável.
Desvantagens dos Contêineres Linux
Os contêineres Linux (LXC) são uma tecnologia popular para virtualização de aplicativos e sistemas operacionais. No entanto, assim como qualquer tecnologia, eles apresentam algumas desvantagens que devem ser consideradas. Nesta seção, serão discutidas as desvantagens relacionadas à segurança e compatibilidade.
Segurança
Uma das principais preocupações com os contêineres Linux é a segurança. Como os contêineres compartilham o mesmo kernel do host, existe o risco de um contêiner comprometido afetar outros contêineres e o próprio sistema operacional host. Além disso, os contêineres são executados com privilégios de usuário elevados, o que pode permitir que um invasor ganhe acesso ao sistema host.
Para mitigar esses riscos, é importante implementar medidas de segurança, como a execução dos contêineres em um ambiente isolado, a aplicação de políticas de segurança rigorosas e a utilização de ferramentas de monitoramento e detecção de ameaças.
Compatibilidade
Outra desvantagem dos contêineres Linux é a compatibilidade. Embora os contêineres sejam projetados para serem portáteis e executados em qualquer sistema operacional Linux, pode haver problemas de compatibilidade com aplicativos que dependem de bibliotecas específicas ou configurações de sistema operacional. Além disso, a compatibilidade pode ser afetada por diferenças de versão do kernel ou configurações de rede.
Para garantir a compatibilidade, é importante testar os contêineres em diferentes ambientes e sistemas operacionais, bem como garantir que as dependências do aplicativo sejam instaladas corretamente dentro do contêiner. Além disso, é importante manter os contêineres atualizados com as versões mais recentes das bibliotecas e do sistema operacional.
Como usar Contêineres Linux
Os contêineres Linux são uma tecnologia de virtualização que permite a execução de múltiplos sistemas operacionais isolados em uma única máquina física. Nesta seção, serão apresentados os passos necessários para instalar, configurar e criar e gerenciar contêineres Linux.
Instalação
Para instalar o LXC, é necessário adicionar o repositório do LXC e atualizar o sistema operacional. Em seguida, pode-se instalar o LXC e as ferramentas necessárias para criar e gerenciar contêineres. O comando abaixo pode ser usado para instalar o LXC e as ferramentas no Ubuntu:
sudo apt-get install lxc lxc-templates lxc-utils
Configuração
Após a instalação, é necessário configurar o LXC para permitir o uso de contêineres. O primeiro passo é carregar o módulo do kernel LXC. Isso pode ser feito com o seguinte comando:
sudo modprobe lxc
Em seguida, é necessário configurar a rede do LXC para permitir que os contêineres possam se comunicar com a rede externa. Isso pode ser feito adicionando a seguinte linha ao arquivo /etc/default/lxc-net:
USE_LXC_BRIDGE="true"
Criação e Gerenciamento
Para criar um contêiner Linux, é necessário usar o comando lxc-create. É possível escolher uma das várias imagens disponíveis no repositório do LXC ou criar uma imagem personalizada. O comando abaixo cria um contêiner com a imagem Ubuntu 20.04:
sudo lxc-create -t ubuntu -n meu-container
Após a criação do contêiner, é possível iniciar, parar e reiniciar o contêiner usando os comandos lxc-start, lxc-stop e lxc-restart, respectivamente. Também é possível acessar o console do contêiner usando o comando lxc-console.
O gerenciamento dos contêineres pode ser feito usando o comando lxc-ls, que lista todos os contêineres criados. O comando lxc-info exibe informações sobre um contêiner específico, como o endereço IP e o status. É possível também modificar as configurações do contêiner usando o comando lxc-config.
Casos de uso de Contêineres Linux
Os contêineres Linux (LXC) são uma tecnologia cada vez mais popular para virtualização de aplicativos e serviços. Eles oferecem uma maneira eficiente e flexível de encapsular aplicativos em ambientes isolados, permitindo que eles sejam executados em uma variedade de plataformas e sistemas operacionais.
Aqui estão alguns casos de uso comuns para contêineres Linux:
1. Desenvolvimento e Teste
Os contêineres Linux são frequentemente usados por desenvolvedores para criar ambientes de desenvolvimento e teste isolados. Isso permite que eles testem o código em diferentes plataformas e configurações sem afetar o ambiente de produção. Os contêineres também podem ser facilmente replicados e compartilhados entre desenvolvedores, facilitando a colaboração em projetos.
2. Implantação de Aplicativos
Os contêineres Linux são uma maneira popular de implantar aplicativos em ambientes de produção. Eles fornecem uma maneira consistente de empacotar e distribuir aplicativos, garantindo que eles sejam executados de maneira confiável em diferentes plataformas e sistemas operacionais. Os contêineres também podem ser facilmente escalados e gerenciados em um cluster de servidores.
3. Virtualização de Servidores
Os contêineres Linux podem ser usados para virtualizar servidores, permitindo que vários serviços e aplicativos sejam executados em um único servidor físico. Isso ajuda a maximizar a utilização dos recursos do servidor e reduzir os custos de infraestrutura. Os contêineres também permitem que os serviços sejam isolados uns dos outros, fornecendo segurança adicional.
4. Migração de Aplicativos
Os contêineres Linux podem ser usados para migrar aplicativos entre diferentes plataformas e sistemas operacionais. Eles fornecem uma maneira fácil de encapsular um aplicativo e suas dependências, permitindo que ele seja movido para um novo ambiente sem a necessidade de reescrever o código. Isso pode ser útil para empresas que desejam migrar aplicativos para a nuvem ou para uma plataforma diferente.
Em resumo, os contêineres Linux são uma tecnologia versátil e poderosa que pode ser usada para uma variedade de casos de uso. Eles oferecem uma maneira eficiente e flexível de virtualizar aplicativos e serviços, permitindo que eles sejam executados em uma variedade de plataformas e sistemas operacionais.
Comparação com outras tecnologias
Docker
O Docker é uma tecnologia de contêiner muito popular que é frequentemente comparada ao LXC. Enquanto o LXC é uma tecnologia de contêiner baseada no kernel do Linux, o Docker é uma plataforma de contêinerização que utiliza o LXC como uma de suas tecnologias subjacentes. O Docker é frequentemente usado em ambientes de desenvolvimento, testes e produção, pois é fácil de usar e permite que os desenvolvedores criem e implantem aplicativos em contêineres de maneira rápida e eficiente.
Kubernetes
O Kubernetes é uma plataforma de orquestração de contêineres que é frequentemente usada em conjunto com o Docker. O Kubernetes permite que os desenvolvedores gerenciem e escalonem contêineres em larga escala, tornando-o uma escolha popular para empresas que precisam implantar aplicativos em grande escala. Embora o LXC possa ser usado com o Kubernetes, muitas empresas optam pelo Docker devido à sua popularidade e facilidade de uso.
Em resumo, o LXC é uma tecnologia de contêiner baseada no kernel do Linux que é frequentemente usada em conjunto com outras tecnologias de contêiner, como o Docker e o Kubernetes. Cada tecnologia tem seus próprios pontos fortes e fracos, e a escolha dependerá das necessidades específicas de cada empresa.
Conclusão
Em resumo, os Linux Containers (LXC) são uma tecnologia promissora para a virtualização de aplicações. Eles oferecem um ambiente isolado e seguro para a execução de programas, permitindo que os usuários executem várias aplicações em um único sistema operacional. Além disso, eles são leves e rápidos, o que os torna ideais para ambientes de desenvolvimento e produção.
No entanto, é importante notar que os LXC não são uma solução para todos os casos de uso. Eles são mais adequados para a execução de aplicações isoladas, em vez de sistemas operacionais inteiros. Além disso, a configuração e a manutenção de contêineres LXC podem ser complexas e exigir conhecimentos avançados de Linux.
Em suma, os Linux Containers (LXC) são uma tecnologia poderosa que pode ajudar a aumentar a eficiência e a segurança da virtualização de aplicações. No entanto, é importante avaliar cuidadosamente se eles são a solução certa para o seu caso de uso específico antes de adotá-los.
Testes Unitários são uma técnica de programação utilizada para testar pequenas partes do código de um software.
Compartilhar
Pedro Mendes Publicado há 8 months atrás.
Testes Unitários são uma técnica de programação utilizada para testar pequenas partes do código de um software. Esses testes são realizados em unidades individuais de código, como funções ou métodos, para garantir que cada uma delas esteja funcionando corretamente.
Os testes unitários são importantes porque ajudam a identificar erros e problemas em um estágio inicial do desenvolvimento do software, o que pode economizar tempo e recursos no longo prazo. Além disso, eles fornecem uma maneira de garantir que as alterações feitas no código não afetem negativamente outras partes do software.
Embora os testes unitários possam ser demorados e trabalhosos de escrever, eles são uma parte essencial do processo de desenvolvimento de software e podem ajudar a garantir a qualidade e a confiabilidade do produto final. Com a crescente demanda por software de alta qualidade e a necessidade de desenvolvimento ágil, os testes unitários estão se tornando cada vez mais importantes para empresas e desenvolvedores individuais.
Conceito de Testes Unitários
Testes Unitários são uma técnica de teste de software que consiste em testar individualmente as unidades de código, ou seja, as menores partes do software que podem ser testadas isoladamente. Essas unidades são geralmente funções, métodos ou classes.
O objetivo dos Testes Unitários é garantir que cada unidade de código esteja funcionando corretamente, de acordo com as especificações e requisitos. Isso ajuda a identificar erros e falhas de forma precoce, evitando que esses problemas se propaguem para outras partes do software.
Para realizar Testes Unitários, é necessário escrever códigos de teste que verifiquem se a unidade de código está produzindo o resultado esperado. Esses códigos de teste são executados automaticamente e podem ser integrados ao processo de desenvolvimento de software.
Ao utilizar Testes Unitários, é possível aumentar a qualidade do software, reduzir o tempo de desenvolvimento e minimizar os custos de manutenção. Além disso, essa técnica pode ajudar a melhorar a comunicação entre os membros da equipe de desenvolvimento e a documentação do software.
Em resumo, Testes Unitários são uma técnica essencial para garantir a qualidade do software, identificar erros precocemente e melhorar a eficiência do processo de desenvolvimento.
Importância dos Testes Unitários
Testes unitários são uma parte fundamental do desenvolvimento de software. Eles são responsáveis por testar as unidades individuais de código, como funções, métodos e classes, isoladamente do resto do sistema. Isso permite que os desenvolvedores identifiquem e corrijam erros antes que eles se tornem um problema maior.
Ao escrever testes unitários, os desenvolvedores podem garantir que seus códigos estão funcionando corretamente e que as alterações que fazem não afetam outras partes do sistema. Isso ajuda a garantir que o software seja robusto e confiável.
Além disso, os testes unitários facilitam a manutenção do código. Quando um desenvolvedor precisa fazer uma alteração em uma parte do sistema, ele pode executar os testes unitários para garantir que as alterações não afetem outras partes do sistema. Isso ajuda a reduzir o tempo e o custo de manutenção do software.
Outra vantagem dos testes unitários é que eles ajudam a documentar o código. Ao escrever testes para cada unidade de código, os desenvolvedores estão essencialmente criando uma documentação para o código. Isso pode ajudar outros desenvolvedores a entender o funcionamento do sistema e a fazer alterações com mais facilidade.
Em resumo, os testes unitários são uma parte essencial do desenvolvimento de software. Eles ajudam a garantir que o software seja robusto, confiável e fácil de manter.
Princípios dos Testes Unitários
Os testes unitários são uma técnica de teste de software que se concentra na verificação do comportamento de unidades individuais de código. Eles são escritos pelos desenvolvedores para garantir que cada parte do código funcione corretamente e de acordo com as especificações.
Existem alguns princípios básicos que os desenvolvedores devem seguir ao escrever testes unitários. Esses princípios ajudam a garantir que os testes sejam eficazes e fáceis de manter.
Princípio da clareza
Os testes unitários devem ser claros e fáceis de entender. Isso significa que eles devem ser escritos em uma linguagem simples e direta, com nomes de métodos e variáveis que reflitam claramente o que está sendo testado.
Princípio da independência
Cada teste unitário deve ser independente dos outros testes. Isso significa que cada teste deve ser executado em um ambiente isolado, sem depender de outros testes para serem executados corretamente.
Princípio da repetibilidade
Os testes unitários devem ser repetíveis. Isso significa que eles devem produzir os mesmos resultados sempre que forem executados, independentemente do ambiente em que são executados.
Princípio da abrangência
Os testes unitários devem cobrir todas as partes do código que podem falhar. Isso significa que cada método, função ou bloco de código deve ter pelo menos um teste associado a ele.
Princípio da rapidez
Os testes unitários devem ser rápidos. Isso significa que eles devem ser executados rapidamente para que possam ser executados com frequência durante o processo de desenvolvimento. Testes lentos podem desencorajar os desenvolvedores a executá-los com frequência.
Seguindo esses princípios, os desenvolvedores podem escrever testes unitários eficazes que ajudam a garantir a qualidade do código e a acelerar o processo de desenvolvimento.
Ferramentas para Testes Unitários
Existem diversas ferramentas disponíveis para realizar testes unitários em diferentes linguagens de programação. A seguir, serão apresentadas algumas das principais ferramentas utilizadas para testes unitários em Java, C# e Python.
JUnit
O JUnit é uma das ferramentas mais populares para testes unitários em Java. Ele permite a criação de testes simples e eficientes, além de ser integrado a diversas ferramentas de desenvolvimento. O JUnit possui diversas funcionalidades, como asserções, testes parametrizados, testes de exceção e testes de tempo.
NUnit
O NUnit é uma ferramenta para testes unitários em C#. Ele é uma versão portada do JUnit para a plataforma .NET. O NUnit permite a criação de testes simples e eficientes, além de ser integrado a diversas ferramentas de desenvolvimento. O NUnit possui diversas funcionalidades, como asserções, testes parametrizados, testes de exceção e testes de tempo.
TestNG
O TestNG é uma ferramenta para testes unitários em Java. Ele foi criado para superar as limitações do JUnit e oferecer uma solução mais avançada e flexível. O TestNG permite a criação de testes simples e eficientes, além de ser integrado a diversas ferramentas de desenvolvimento. O TestNG possui diversas funcionalidades, como asserções, testes parametrizados, testes de exceção e testes de tempo.
Em resumo, as ferramentas para testes unitários são essenciais para garantir a qualidade do código produzido. É importante escolher a ferramenta adequada para cada projeto e linguagem de programação, levando em consideração as funcionalidades e integrações oferecidas.
Implementação de Testes Unitários
Os testes unitários são uma parte importante do processo de desenvolvimento de software. Eles permitem que os desenvolvedores testem o código em pequenas partes, garantindo que cada parte do código esteja funcionando corretamente antes de ser integrada com outras partes do sistema. A implementação de testes unitários pode ajudar a garantir a qualidade do software e reduzir o tempo de desenvolvimento.
Estrutura de um Teste Unitário
Um teste unitário consiste em três partes principais: a preparação, a execução e a verificação. Na preparação, o desenvolvedor configura o ambiente de teste, criando objetos e definindo variáveis. Na execução, o desenvolvedor executa o código que está sendo testado. Na verificação, o desenvolvedor verifica se o resultado da execução é o esperado.
Asserts
Os asserts são usados para verificar se o resultado da execução é o esperado. Eles são usados para comparar o resultado da execução com um valor esperado. Se o resultado da execução for diferente do valor esperado, o teste falhará.
Testes de Exceções
Os testes de exceções são usados para verificar se o código está tratando exceções corretamente. Eles são usados para verificar se o código está lidando corretamente com erros e exceções. Isso é importante porque erros e exceções podem ocorrer durante a execução do código e podem causar falhas no sistema.
A implementação de testes unitários pode ser uma tarefa desafiadora, mas é uma parte importante do processo de desenvolvimento de software. Ao implementar testes unitários, os desenvolvedores podem garantir que o código está funcionando corretamente e reduzir o tempo de desenvolvimento. Com a estrutura correta de um teste unitário, o uso de asserts e testes de exceções, os desenvolvedores podem garantir a qualidade do software e melhorar a confiança no código que estão produzindo.
Boas Práticas em Testes Unitários
Independência de Testes
Uma das boas práticas em testes unitários é garantir que cada teste seja independente dos outros. Isso significa que cada teste deve ser capaz de rodar sozinho, sem depender de outros testes ou do estado de outros testes. Isso garante que se um teste falhar, não afetará os outros testes e facilitará a identificação do problema.
Testes Pequenos e Focados
Outra boa prática em testes unitários é manter os testes pequenos e focados. Cada teste deve testar apenas uma funcionalidade específica do código, o que torna mais fácil identificar o problema caso o teste falhe. Além disso, testes pequenos e focados são mais fáceis de manter e executar.
Nomeação de Testes
A nomeação correta dos testes é fundamental para a clareza e organização do código. Os nomes dos testes devem ser descritivos e indicar qual funcionalidade está sendo testada. Isso ajuda a identificar rapidamente quais testes estão falhando e a entender o propósito de cada teste.
Em resumo, seguir boas práticas em testes unitários é fundamental para garantir a qualidade do código e facilitar a identificação e correção de problemas. Independência de testes, testes pequenos e focados e nomeação correta dos testes são algumas das práticas que podem ser adotadas para melhorar a eficácia dos testes unitários.
Desafios dos Testes Unitários
Os testes unitários são uma prática fundamental para garantir a qualidade do código. No entanto, eles também apresentam alguns desafios que precisam ser superados para que sejam eficazes.
Um dos principais desafios é a dificuldade de encontrar o equilíbrio entre a cobertura de código e o tempo de execução dos testes. Testes com alta cobertura podem levar muito tempo para serem executados, o que pode atrasar o desenvolvimento e tornar o processo menos eficiente.
Outro desafio é a manutenção dos testes. À medida que o código evolui, os testes precisam ser atualizados para refletir as mudanças. Isso pode ser uma tarefa tediosa e demorada, especialmente em projetos grandes e complexos.
Além disso, os testes unitários podem não detectar todos os problemas do código. Eles geralmente se concentram em testar pequenas partes do código isoladamente, o que pode não capturar problemas que surgem quando essas partes interagem umas com as outras.
Para superar esses desafios, é importante adotar boas práticas de teste, como escrever testes simples e fáceis de manter, usar ferramentas que ajudem a automatizar o processo de teste e encontrar o equilíbrio certo entre a cobertura de código e o tempo de execução dos testes. Com essas práticas, os testes unitários podem ser uma ferramenta poderosa para garantir a qualidade do código e acelerar o desenvolvimento.
Conclusão
Os testes unitários são uma parte essencial do processo de desenvolvimento de software. Eles permitem que os desenvolvedores verifiquem se o código que estão escrevendo funciona corretamente e atende aos requisitos do projeto.
Ao longo deste artigo, foram discutidos vários aspectos dos testes unitários, incluindo sua definição, benefícios, tipos e exemplos de implementação. Também foram apresentados alguns dos principais frameworks de teste unitário disponíveis para a linguagem de programação Java.
Os testes unitários são uma prática importante para garantir a qualidade do software e reduzir o tempo de desenvolvimento. Eles permitem que os desenvolvedores identifiquem e corrijam erros no código de forma rápida e eficiente. Além disso, os testes unitários ajudam a documentar o código e torná-lo mais fácil de entender e manter.
Em conclusão, os testes unitários são uma parte vital do processo de desenvolvimento de software. Eles devem ser implementados em todos os projetos de software para garantir a qualidade e a eficiência do código. Com a ajuda dos frameworks de teste unitário disponíveis, os desenvolvedores podem facilmente implementar testes unitários em seus projetos e colher os benefícios de uma abordagem de desenvolvimento orientada a testes.
SRE visa garantir a confiabilidade, disponibilidade, escalabilidade e eficiência dos sistemas de computação.
Compartilhar
Pedro Mendes Publicado há 8 months atrás.
SRE, do inglês Site Reliability Engineering (ou Engenharia de Confiabilidade de Site) é uma metodologia de engenharia de software que visa garantir a confiabilidade, disponibilidade, escalabilidade e eficiência dos sistemas de computação. O objetivo principal do SRE é minimizar o tempo de inatividade e garantir que os serviços prestados sejam confiáveis e escaláveis.
O SRE é uma disciplina relativamente nova, que surgiu em resposta à crescente complexidade dos sistemas de computação modernos. À medida que as empresas se tornam mais dependentes de sistemas de computação para fornecer serviços e gerenciar operações, a necessidade de garantir a confiabilidade e a disponibilidade desses sistemas se torna cada vez mais crítica. O SRE fornece uma estrutura para garantir que os sistemas de computação sejam projetados, construídos e operados de forma confiável e eficiente.
Conceitos Básicos de SRE
Site Reliability Engineering (SRE) é uma abordagem de engenharia de software que visa melhorar a confiabilidade e a disponibilidade dos sistemas. SRE é uma disciplina que combina habilidades de desenvolvimento de software e operações de TI para criar sistemas altamente escaláveis e resilientes.
Os SREs são responsáveis por garantir que os sistemas e aplicativos estejam disponíveis e funcionando corretamente. Eles trabalham em estreita colaboração com os desenvolvedores de software e equipes de operações para garantir que os sistemas sejam projetados, implementados e mantidos de maneira confiável.
Os SREs usam várias ferramentas e técnicas para melhorar a confiabilidade do sistema. Eles usam monitoramento e alertas para detectar problemas antes que eles afetem os usuários. Eles também usam técnicas de automação para reduzir o tempo de inatividade e aumentar a eficiência.
Além disso, os SREs são responsáveis por garantir que os sistemas sejam seguros e protegidos contra ameaças externas. Eles trabalham em estreita colaboração com as equipes de segurança para garantir que os sistemas sejam projetados com segurança desde o início e que as melhores práticas de segurança sejam seguidas em todos os momentos.
Em resumo, SRE é uma disciplina que combina habilidades de desenvolvimento de software e operações de TI para criar sistemas altamente escaláveis, confiáveis e resilientes. Os SREs são responsáveis por garantir que os sistemas estejam disponíveis e funcionando corretamente, usando várias ferramentas e técnicas para melhorar a confiabilidade e a segurança do sistema.
História da SRE
Origens
A Engenharia de Confiabilidade de Sites (SRE) surgiu em 2003 dentro do Google, como uma resposta aos problemas enfrentados pela empresa em relação à confiabilidade e disponibilidade de seus serviços. A equipe de SRE foi criada para trabalhar em conjunto com a equipe de desenvolvimento de software, com o objetivo de garantir que os serviços do Google fossem confiáveis e resilientes.
Desenvolvimento e Crescimento
Com o tempo, a equipe de SRE do Google cresceu e se tornou uma parte fundamental da empresa. A equipe de SRE foi responsável por desenvolver ferramentas e práticas que ajudaram a melhorar a confiabilidade e a disponibilidade dos serviços do Google. Além disso, a equipe de SRE também foi responsável por compartilhar suas práticas e conhecimentos com outras empresas, ajudando a disseminar a cultura de confiabilidade em toda a indústria de tecnologia.
Nos anos seguintes, o conceito de SRE se espalhou para outras empresas de tecnologia, que também começaram a criar equipes de SRE para garantir a confiabilidade de seus serviços. Hoje, a SRE é uma prática comum em muitas empresas de tecnologia em todo o mundo, e é considerada uma parte fundamental da engenharia de software moderna.
Princípios da SRE
A SRE (Site Reliability Engineering) é uma abordagem para gerenciamento de sistemas que visa garantir que os serviços online estejam sempre disponíveis e funcionando corretamente. Para alcançar esse objetivo, a SRE se baseia em alguns princípios fundamentais.
Automatização
Um dos principais princípios da SRE é a automatização. Automatizar processos é uma forma de reduzir erros humanos e aumentar a eficiência do sistema. A SRE utiliza ferramentas de automação para gerenciar a infraestrutura, implantar novas versões de software e monitorar o sistema.
Mensurabilidade
A mensurabilidade é outro princípio importante da SRE. É preciso medir e monitorar constantemente o desempenho do sistema para identificar problemas e tomar medidas preventivas. A SRE utiliza métricas para avaliar o desempenho do sistema, como tempo de resposta, taxa de erro e disponibilidade.
Redundância
A redundância é um princípio fundamental da SRE para garantir a disponibilidade contínua dos serviços. A SRE utiliza técnicas de redundância, como replicação de dados, balanceamento de carga e failover, para garantir que o sistema esteja sempre disponível, mesmo em caso de falhas.
Com base nesses princípios, a SRE busca garantir que os serviços online estejam sempre disponíveis e funcionando corretamente, minimizando o tempo de inatividade e maximizando a eficiência do sistema.
Práticas de SRE
As práticas de SRE (Site Reliability Engineering) são cruciais para garantir a confiabilidade e disponibilidade de um sistema. Essas práticas incluem o gerenciamento de incidentes, a capacidade de planejamento e a realização de análises pós-incidentes (postmortem).
Postmortem
Um postmortem é uma análise detalhada de um incidente que ocorreu em um sistema. Ele é realizado para entender o que aconteceu, como aconteceu e como evitar que aconteça novamente no futuro. Durante um postmortem, é importante identificar as causas raiz do incidente e propor soluções para prevenir futuros problemas.
Gerenciamento de Incidentes
O gerenciamento de incidentes é uma prática fundamental para garantir a disponibilidade de um sistema. Ele envolve a detecção, o registro, a classificação, a priorização, a resolução e o fechamento de incidentes. É importante ter um plano de ação bem definido para cada tipo de incidente, com etapas claras e definidas para minimizar o impacto do incidente.
Capacidade de Planejamento
A capacidade de planejamento é essencial para garantir a escalabilidade e a disponibilidade de um sistema. Ela envolve a análise de dados históricos e o uso de ferramentas de monitoramento para prever e planejar a capacidade necessária para atender à demanda esperada. É importante ter um plano de capacidade bem definido para garantir que o sistema possa lidar com a carga esperada sem comprometer a disponibilidade.
Habilidades do Engenheiro SRE
O Engenheiro SRE (Site Reliability Engineer) é responsável por garantir a confiabilidade e disponibilidade dos sistemas de TI. Para desempenhar essa função, ele precisa ter diversas habilidades técnicas, de comunicação e de gerenciamento de crises.
Habilidades Técnicas
O Engenheiro SRE precisa ter um conhecimento sólido em programação e em sistemas operacionais. Ele deve ser capaz de escrever códigos eficientes, automatizar processos e identificar gargalos de performance. Além disso, ele precisa ter conhecimento em:
Sistemas de monitoramento e alerta;
Bancos de dados;
Redes de computadores;
Segurança da informação.
Habilidades de Comunicação
O Engenheiro SRE precisa ser capaz de se comunicar bem com outros membros da equipe de TI e com outras áreas da empresa. Ele precisa ser capaz de explicar problemas técnicos de forma clara e concisa para pessoas que não têm conhecimento técnico. Além disso, ele deve ser capaz de:
Documentar processos e procedimentos;
Elaborar relatórios e apresentações;
Participar de reuniões e apresentar soluções.
Habilidades de Gerenciamento de Crise
O Engenheiro SRE precisa estar preparado para lidar com crises e situações de emergência. Ele deve ser capaz de identificar rapidamente problemas e tomar medidas para resolvê-los. Além disso, ele precisa ter habilidades em:
Gerenciamento de incidentes;
Análise de causa raiz;
Planejamento de contingência;
Tomada de decisão sob pressão.
Em resumo, o Engenheiro SRE é um profissional com habilidades técnicas, de comunicação e de gerenciamento de crises. Ele é essencial para garantir a confiabilidade e disponibilidade dos sistemas de TI de uma empresa.
Desafios e Soluções em SRE
A área de SRE (Site Reliability Engineering) é responsável por garantir a disponibilidade, confiabilidade e escalabilidade dos sistemas. No entanto, há vários desafios que podem surgir no caminho para atingir esses objetivos. Nesta seção, serão apresentados alguns dos principais desafios enfrentados pelos profissionais de SRE e as soluções para superá-los.
Balanceamento de Carga
Um dos principais desafios em SRE é o balanceamento de carga. Em sistemas com alto volume de tráfego, é preciso distribuir a carga de forma equilibrada entre os servidores para evitar sobrecargas e garantir a disponibilidade do sistema. Para isso, é possível utilizar ferramentas de balanceamento de carga, como o HAProxy e o NGINX, que permitem distribuir a carga entre vários servidores de forma inteligente.
Latência
Outro desafio comum em SRE é a latência. A latência é o tempo que um sistema leva para responder a uma solicitação. Em sistemas com alto volume de tráfego, a latência pode aumentar significativamente, o que pode afetar a experiência do usuário e a disponibilidade do sistema. Para reduzir a latência, é possível utilizar técnicas como o cache de dados e a otimização do código.
Escalabilidade
A escalabilidade é outro desafio em SRE. Em sistemas com alto volume de tráfego, é preciso garantir que o sistema seja capaz de crescer de forma sustentável. Para isso, é preciso utilizar técnicas como a distribuição de carga, o uso de serviços em nuvem e a otimização do código. Além disso, é importante monitorar constantemente o sistema e fazer ajustes para garantir que ele continue escalável ao longo do tempo.
Em resumo, a área de SRE apresenta vários desafios, mas com as soluções adequadas é possível superá-los e garantir a disponibilidade, confiabilidade e escalabilidade dos sistemas.
Futuro da SRE
A SRE (Site Reliability Engineering) é uma disciplina relativamente nova que tem evoluído rapidamente nos últimos anos. Com a crescente adoção de práticas DevOps e a necessidade de garantir a confiabilidade dos sistemas, a SRE se tornou uma área essencial para as empresas que desejam manter sua presença online.
No futuro, espera-se que a SRE continue a evoluir e se adaptar às novas tecnologias e tendências de mercado. Algumas das principais tendências que podem influenciar o futuro da SRE incluem:
Automação: A automação é uma parte fundamental da SRE e é provável que continue a desempenhar um papel importante no futuro. À medida que as empresas adotam cada vez mais a automação, a SRE precisará se adaptar para garantir que os sistemas estejam sempre operando de forma confiável.
Aumento da complexidade: À medida que os sistemas se tornam cada vez mais complexos, a SRE precisará se adaptar para lidar com esses desafios. Isso pode incluir o uso de novas ferramentas e tecnologias para monitorar e gerenciar sistemas complexos.
Integração com outras áreas: À medida que a SRE se torna mais estabelecida, é provável que ela se integre mais estreitamente com outras áreas, como desenvolvimento de software e segurança da informação. Isso pode ajudar a garantir que os sistemas sejam desenvolvidos e gerenciados de forma mais holística.
No geral, o futuro da SRE parece brilhante. À medida que as empresas continuam a depender cada vez mais de seus sistemas online, a SRE se tornará cada vez mais importante para garantir que esses sistemas sejam confiáveis e estejam sempre disponíveis. Com a evolução constante da tecnologia e das práticas de negócios, a SRE continuará a evoluir e se adaptar para atender às necessidades das empresas modernas.
Microsserviços Prontos Para a Produção, por Susan J. Fowler
O livro se propõe a ser um guia do desenvolvimento de microsserviços. Mas será que ele cumpre o que promete?
Compartilhar
Pedro Mendes Publicado há 8 months atrás.
No livro “Microsserviços Prontos Para a Produção: Construindo Sistemas Padronizados em uma Organização de Engenharia de Software”, a autora Susan J. Fowler compartilha sua experiência ao abordar os desafios comuns enfrentados ao construir microsserviços.
O livro oferece uma visão prática baseada em casos reais sobre como projetar, implementar e manter microsserviços escaláveis e confiáveis.
Porém o livro também tem pontos a serem considerados, que precisam ser levados em conta. Antes de decidir sobre comprar (ou não) o livro, confira as críticas do nosso post. Vamos lá!
Sobre o Livro
Em suas 268 páginas, o livro destaca a importância da padronização para garantir a consistência em toda a organização de engenharia. Fowler, a autora, explora conceitos como automação, monitoramento e resiliência, apresentando estratégias para enfrentar problemas complexos, como a gestão de dados, falhas, integração contínua e o processo de deploy.
Além disso, o livro aborda temas importantes como testes, documentação e a cultura de colaboração para o sucesso contínuo dos microsserviços.
Ao longo do livro, Fowler não apenas oferece princípios teóricos, mas também compartilha lições aprendidas em situações do mundo real das empresas de tecnologia por onde passou, tais como a Uber, Stripe e New York Times.
O livro busca ser uma leitura de fácil acesso para desenvolvedores, arquitetos de software e líderes de equipe que buscam implementar microsserviços em suas organizações. Porém, existe algumas considerações que você precisa fazer antes de comprar o livro. Na próxima sessão destacaremos elas.
Para quem o livro de destina
Desenvolvedores, arquitetos e gestores podem se beneficiar do livro.
O livro é recomendado para profissionais de tecnologia que estão iniciando sua jornada no mundo dos microsserviços – em especial desenvolvedores juniores ou plenos que desejam criar compreensão dos pontos importantes no desenvolvimento de microsserviços.
A autora, Susan J. Fowler, aborda os conceitos de forma acessível, tornando o livro uma espécie de guia rápido para aqueles que estão se familiarizando com os desafios e as práticas mais comuns associadas ao tema.
Além disso, este livro pode servir como um manual prático para gerentes, POs e estagiários. Embora pessoas com mais experiência possam considerar o conteúdo um pouco raso, a abordagem abrangente de Fowler oferece recomendações para aqueles que desejam entender não apenas os aspectos técnicos, mas também os aspectos organizacionais e estratégicos associados à implementação de microsserviços.
Para profissionais em funções de gestão de software, este livro é uma boa opção para iniciar no tema microsserviços. Com pouco mais de 250 páginas, é uma leitura concisa, cobrindo tópicos em alto nível com o mínimo de detalhes para fornecer uma compreensão prática.
Pontos Fortes
Pontos fortes do livro
1
O livro apresenta uma linguagem clara, tornando-o facilmente compreensível para uma variedade de leitores, independentemente de sua experiência em desenvolvimento de software.
2
Servindo como um guia rápido, a obra abrange as boas práticas de arquitetura, comunicação entre sistemas, monitoramento, alarmes, plantões de equipe, entre outros aspectos essenciais para o sucesso na implementação de microsserviços.
3
Sua razoável atualização reflete a relevância contínua do conteúdo, garantindo que os leitores tenham acesso a informações minimamente alinhadas com as tendências mais recentes no desenvolvimento de sistemas distribuídos.
4
Os diversos checklists fornecidos pelo livro oferecem uma abordagem prática e aplicável, auxiliando na identificação de potenciais problemas de qualidade em suas arquiteturas, contribuindo para a construção de sistemas mais robustos.
5
Com um preço razoavelmente acessível, o livro se destaca como uma opção interessante para aqueles que buscam aprimorar seus conhecimentos em um bom custo-benefício.
Pontos Fracos
Pontos fracos do livro
1
Para profissionais com alguma experiência prévia, o livro pode ser excessivamente introdutório, oferecendo informações consideradas básicas.
2
Apesar de abordar uma ampla variedade de tópicos, o livro tende a tratar cada um deles de maneira superficial. Essa abordagem pode deixar alguns leitores insatisfeitos, necessitando um aprofundamento mais detalhado dos conceitos.
3
A obra concentra-se principalmente no “o que” precisa ser feito, deixando a desejar na explicação do “como”. Esse enfoque força os leitores a constantemente buscar orientações mais detalhadas em outras fontes.
Vale a pena comprar?
Quem deve comprar o livro?
Recomendamos a compra do livro “Microsserviços Prontos Para a Produção” para aqueles que buscam uma introdução clara e acessível ao universo dos microsserviços.
Seu formato de guia rápido abrange de maneira direta boas práticas de arquitetura, comunicação entre sistemas, monitoramento e outros elementos cruciais para o êxito na implementação de microsserviços.
Além disso, a inclusão de checklists práticos proporciona uma ferramenta valiosa para identificar potenciais problemas de qualidade em suas arquiteturas. Considerando o preço acessível, o livro entra na categoria “bom custo-benefício” para aqueles que buscam aprimorar seus conhecimentos.
Contudo, é importante destacar que o livro pode ser considerado superficial por leitores mais experientes, abordando os tópicos de maneira introdutória. A concentração no “o que” em detrimento do “como” pode deixar alguns leitores em busca de uma orientação mais detalhada em fontes externas.
Portanto, a recomendação de compra irá depender se os pontos positivos justificam a aquisição, especialmente para aqueles que estão no início de sua jornada no desenvolvimento de microsserviços.
Onde comprar?
A principal loja atualmente vendendo o livro é a Amazon, porém a editora também disponibiliza a compra através de outros endereços online. A lista completa de opções estão aqui.
Susan J. Fowler é uma engenheira de software, autora, jornalista, roteirista e editora, conhecida por sua contribuição para o campo de microsserviços. Fowler atuou na área de SRE em empresas de tecnologia, incluindo Uber, Stripe e New York Times.
Em sua formação acadêmica, ela participou de estudos em física e filosofia na Universidade da Pensilvânia, onde se envolveu na área de física experimental, contribuindo para o desenvolvimento de hardware e software para detectores de partículas no Experimento ATLAS.
Seu livro “Production-Ready Microservices” reflete não apenas sua experiência prática, mas também sua capacidade de comunicar conceitos de forma acessível. Fowler é uma voz ativa no cenário da engenharia de software e SRE, destacando-se não apenas por suas realizações técnicas, mas também por sua liderança em questões sociais dentro da indústria.
Sobre a Editora
A Novatec Editora, destaca-se por sua especialização na publicação de livros técnicos nas áreas de informática, marketing, negócios, finanças e investimentos. Com uma trajetória de 25 anos, foi pioneira na abordagem de temas relacionados à informática desde sua criação. O nome “Novatec” reflete a fusão entre “nova” e “tecnologia”, evidenciando sua especialização no campo da informática.
Ao longo dos anos, a Novatec consolidou sua presença no mercado editorial com a coleção dos “Guias de Consulta Rápida”, abordando assuntos específicos de forma acessível e prática. A partir de 2009, a Novatec estabeleceu parcerias com editoras estrangeiras, traduzindo e publicando obras internacionais em português para atender às demandas do público brasileiro.
Uma parceria significativa foi estabelecida com a renomada editora americana O’Reilly, resultando na introdução de publicações relevantes sobre desenvolvimento para dispositivos móveis, JavaScript, jQuery, Arduino, Data Mining, ecommerce, marketing, entre outros temas.
Além da O’Reilly, a Novatec também firmou parcerias com editoras como Manning e Apress, ampliando ainda mais o catálogo disponível para leitores brasileiros.
Esse post não é um artigo de conteúdo publicitário e não foi patrocinado. Porém, alguns links de recomendação de compra podem estar vinculados a programas de afiliação em sites parceiros.
O Padrão de Arquitetura SAGA é um modelo que tem como objetivo simplificar a implementação de sistemas distribuídos, robustos e escaláveis.
Compartilhar
Pedro Mendes Publicado há 9 months atrás.
O padrão de arquitetura SAGA é um modelo que tem como objetivo simplificar a implementação de sistemas distribuídos, robustos e escaláveis.
O padrão SAGA foi inicialmente proposto para lidar com transações distribuídas em sistemas, mas pode ser aplicado em uma variedade de cenários. Ele se concentra em dividir as transações em etapas atômicas que podem ser desfeitas ou revertidas se algo der errado. Isso ajuda a garantir que os sistemas sejam consistentes e confiáveis, mesmo em ambientes complexos.
A implementação do padrão SAGA envolve a criação de uma máquina de estado que gerencia as transações e as etapas atômicas. Cada etapa é executada como uma transação separada e pode ser revertida se ocorrer um erro. Isso permite que os sistemas sejam altamente disponíveis e tolerantes a falhas, enquanto ainda mantêm a consistência dos dados.
O padrão SAGA é um modelo arquitetural de aplicações que foi desenvolvido para lidar com problemas de transações distribuídas. Ele é especialmente útil para aplicações que exigem uma alta consistência de dados.
Ele estabelece uma técnica de gerenciamento de transações que registra cada operação que é executada em um sistema distribuído. Cada operação é composta por várias etapas, que podem ser executadas em diferentes serviços.
Uma das principais vantagens do padrão de arquitetura SAGA é que ele permite que as operação sejam executadas de forma assíncrona 👈, o que significa que cada etapa pode ser executada em seu próprio serviço. Isso pode melhorar significativamente a escalabilidade e a flexibilidade do sistema.
Outra vantagem do padrão de arquitetura SAGA é que ele permite que as transações sejam revertidas de forma segura. Se uma etapa da transação falhar, o sistema pode reverter todas as etapas anteriores de forma segura, garantindo que o sistema permaneça em um estado consistente.
No entanto, o padrão de arquitetura SAGA também apresenta alguns desafios. Por exemplo, a implementação do padrão pode ser complexa e requer um bom entendimento de como as transações distribuídas funcionam 😬. Além disso, a implementação de transações reversíveis pode ser difícil em alguns casos.
Origem
SAGA aparece em um paper na Universidade de Princeton.
O aumento no interesse do padrão SAGA pode ser atribuído à evolução das arquiteturas de microsserviços e sistemas distribuídos de grande escala. Porém, as bases do SAGA nascem bem antes: o primeiro estudo sobre o padrão aparece em 1987 em um paper da Universidade Princeton chamado “SAGAS”.
Paper de 1987 que inicia a definição do SAGA baseado em Long Lived Transactions (LLTs)
Com o aumento da complexidade das aplicações distribuídas, surgiram desafios significativos relacionados à consistência de dados e ao gerenciamento de transações em vários serviços interconectados.
Diante desses desafios, os desenvolvedores e arquitetos de sistemas buscaram uma abordagem mais eficaz para resolver tais problemas.
Assim, o padrão SAGA surgiu como uma resposta para atender a essas necessidades, fornecendo uma estrutura flexível e confiável para o gerenciamento de transações distribuídas e operações assíncronas em sistemas complexos.
SAGA e arquiteturas baseadas em eventos
Arquiteturas baseadas em eventos usando um Message Broker
Uma arquitetura baseada em eventos é um modelo de design de software em que os componentes do sistema se comunicam e reagem a eventos gerados interna ou externamente.
Nessa arquitetura, os eventos são usados como a principal forma de comunicação entre os diferentes serviços ou componentes do sistema. Esses eventos podem representar ações significativas, mudanças de estado ou ocorrências importantes no ambiente operacional.
A arquitetura baseada em eventos é projetada para facilitar a escalabilidade, a flexibilidade e a capacidade de resposta do sistema, permitindo que os componentes se comuniquem de maneira assíncrona e reajam a mudanças em tempo real.
O padrão SAGA se torna ainda mais robusto nas arquiteturas baseadas em eventos, mas é possível implementar o SAGA em uma arquitetura de comunicação síncrona.
Transações Distribuídas
Arquitetura baseada em eventos se concentra na comunicação e propagação eficiente de eventos
Tanto a arquitetura SAGA quanto a arquitetura baseada em eventos estão focadas na execução de transações distribuídas em sistemas complexos.
A arquitetura baseada em eventos foca na comunicação e propagação eficiente de eventos dentro do sistema, permitindo que os diferentes componentes reajam a mudanças e atualizações de maneira oportuna.
No padrão SAGA, temos um modelo ainda mais focado na coordenação de operações de compensação e progresso de transações. Veremos mais detalhes no decorrer do post.
Resiliência e Flexibilidade do Sistema
Cada sistema lida com sua carga de trabalho de forma independente dos demais.
Tanto a arquitetura SAGA quanto a arquitetura baseada em eventos contribuem para a resiliência e flexibilidade geral dos serviços, pois permitem que cada um consiga lidar com sua carga de trabalho de forma independente dos demais.
A combinação dessas abordagens reforça a capacidade do sistema de lidar com situações imprevistas e de se adaptar a mudanças.
Componentes do Padrão SAGA
A depender do modelo de solução usado no padrão arquitetura SAGA, podemos encontrar diferentes componentes:
Serviços
Exemplo de serviços que realizam operações de negócios em uma transação distribuída no SAGA
Os serviços são os componentes básicos do modelo SAGA. Eles realizam as operações de negócios em uma transação distribuída. Cada serviço é responsável por uma parte específica da transação e deve ser projetado para ser independente e escalável.
Os serviços podem ser implementados usando qualquer tecnologia de sua escolha, desde que sigam padrões de design para garantir a escalabilidade e a resiliência. Eles devem ser projetados para serem altamente disponíveis e capazes de lidar com grandes volumes de tráfego.
Broker de Mensagens
Exemplos de broker de mensagens
Um broker de mensagens desempenha um papel crucial na arquitetura SAGA baseada em eventos, atuando como um intermediário confiável para facilitar a comunicação assíncrona entre os diferentes serviços e componentes distribuídos.
Ao permitir o envio e recebimento de mensagens entre os vários participantes de uma transação, o broker de mensagens permite a troca de informações de forma confiável e segura, essencial para o funcionamento coordenado das transações distribuídas no contexto do padrão SAGA.
Além disso, o broker de mensagens oferece suporte para controle e encaminhamento de eventos e mensagens em tempo real, garantindo que as diferentes etapas de uma transação sejam executadas de forma previsível.
Com recursos avançados de gerenciamento de filas e tópicos, o broker de mensagens permite que os serviços distribuídos coordenem suas operações de forma eficaz, garantindo a consistência e a integridade dos dados durante todo o processo de transação.
Broker de mensagens usados
As principais tecnologias de mercado frequentemente utilizadas como Broker de Mensagens no padrão SAGA são:
Ao implementar o padrão SAGA em sistemas distribuídos, os desenvolvedores têm a opção de escolher entre dois principais modelos de implementação: Coreografia e Orquestração. Cada um desses modelos apresenta vantagens e desafios distintos, oferecendo abordagens diferentes para lidar com transações distribuídas e o efeitos colaterais delas.
Coreografia
Na coreografia, cada serviço conhece suas responsabilidades e interações com outros serviços.
Em uma arquitetura SAGA baseada em coreografia, as diferentes etapas de uma transação são coordenadas entre os vários serviços envolvidos. Em vez de um componente centralizado controlar todo o processo, cada serviço participante mantém o conhecimento sobre suas próprias responsabilidades e interações com outros serviços.
Quando uma transação é iniciada, cada serviço realiza sua parte das operações e notifica os outros serviços sobre o progresso, geralmente utilizando um broker de mensagens. Essa troca de informações entre os serviços permite que cada um saiba quando é apropriado avançar para a próxima etapa da transação ou se é necessário realizar operações de compensação, caso ocorram problemas.
A arquitetura de coreografia SAGA permite uma comunicação direta e descentralizada entre os serviços, garantindo que a transação avance de forma fluida e consistente.
Essa abordagem descentralizada oferece maior flexibilidade e escalabilidade para lidar com transações distribuídas em sistemas que envolvem múltiplos serviços interconectados.
Exemplos de Coreografia
Exemplo de arquitetura SAGA usando Coreografia 🤓
Exemplo de arquitetura SAGA usando Coreografia
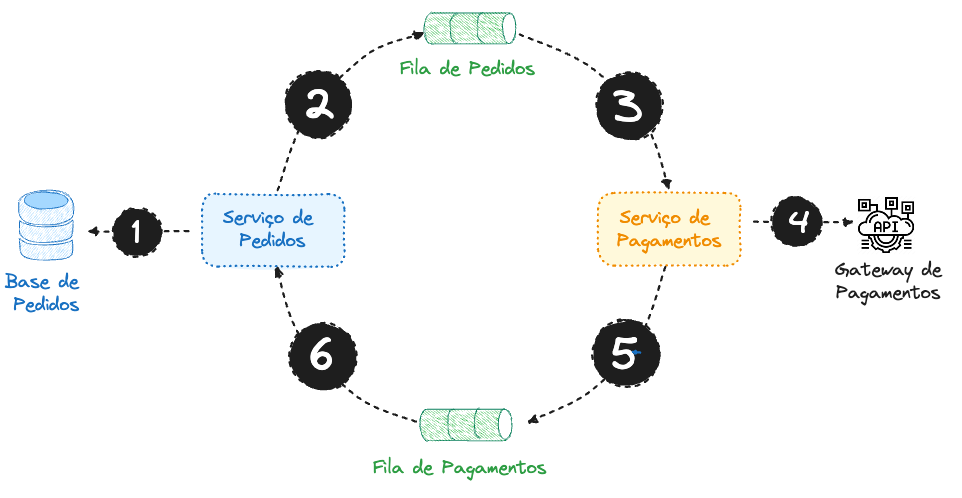
Nesse exemplo, temos a seguinte ordem:
O Serviço de Pedidos cria um registro do Pedido com um status Pendente.
Nesse momento, o Serviço de Pedidos informa ao Serviço de Pagamento sobre o pedido e espera até a obter uma resposta de sucesso ou falha.
O Serviço de Pagamento realiza a tentativa de autorização de pagamento e retorna o resultado para o Serviço de Pedidos. O Serviço de Pedidos por sua vez deve atualizar o status do pedido de acordo com o sucesso ou falha do pagamento.
Exemplo de arquitetura SAGA usando Coreografia com Eventos 🤓
Exemplo de Coreografia (Baseada em Eventos)
Nesse exemplo, temos a seguinte ordem:
O Serviço de Pedidos cria um registro do Pedido com um status Pendente.
Nesse momento, o Serviço de Pedidos emite o evento de Pedido Criado e disponibiliza na Fila de Pedidos.
O Serviço de Pagamento é notificado de um novo pedido.
O Serviço de Pagamento realiza a tentativa de autorização de pagamento.
O Serviço de Pagamento emite um evento para a Fila de Pagamentos com o resultado da autorização de pagamento.
O Serviço de Pedidos agora é notificado com o resultado da tentativa de pagamento, e deve atualizar o status do pedido de acordo com o sucesso ou falha do pagamento.
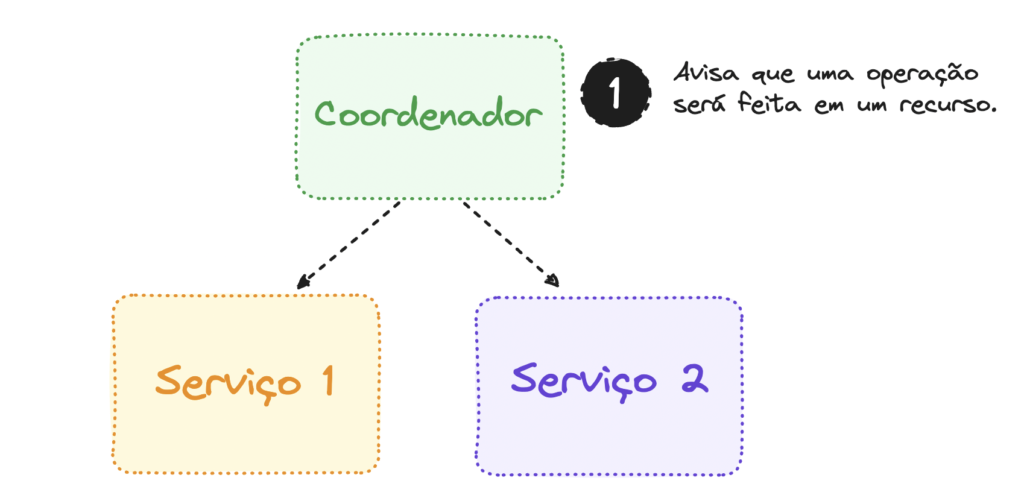
Orquestração
O orquestrador é responsável por coordenar as transações distribuídas entre os diferentes serviços
Em um modelo de arquitetura SAGA baseado em orquestração, o orquestrador é responsável por coordenar as transações distribuídas entre os diferentes serviços. Ele é o ponto central da arquitetura SAGA e garante que todas as transações sejam concluídas com sucesso ou revertidas em caso de falha.
O orquestrador é responsável por acionar o fluxo compensação para reverter transações em caso de falha. Isso significa que, se um serviço falhar durante uma transação, o orquestrador executará uma série de operações para reverter as alterações feitas pelos Serviços que já foram executados.
Exemplos de Orquestração
Exemplo de arquitetura SAGA usando Orquestração 🤓
Exemplo de arquitetura SAGA usando Orquestração
Nesse exemplo, temos a seguinte ordem:
O Orquestrador de Criação de Pedidos é chamado.
O Orquestrador de Criação de Pedidos chama o Serviço de Pedidos informando sobre a criação do pedido e espera até obter uma resposta de sucesso ou erro.
Em caso de sucesso, o Orquestrador de Criação de Pedidos chama o Serviço de Pagamentos e aguarda até obter uma resposta da transação para atualizar o pedido de acordo com o pagamento.
Exemplo de arquitetura SAGA usando Orquestração com Eventos 🤓
Exemplo de arquitetura SAGA usando Orquestração com Eventos
Nesse exemplo, temos a seguinte ordem:
O Orquestrador de Criação de Pedidos é chamado.
O Orquestrador de Criação de Pedidos emite um evento para a Fila de Criação de Serviço, e o Serviço de Pedidos deve consumir e criar o pedido.
Ao criar o pedido, o Serviço de Pedidos emite o evento de Pedido Criado e disponibiliza na Fila de Pedidos Criados.
Após ouvir a emissão de pedido criado, o Orquestrador de Criação de Pedidos deve dar continuidade ao processo, agora emitindo um evento de “Autorização de Pagamento”. O Serviço de Pagamento é notificado de um novo pedido.
Após o Serviço de Pagamento realizar a tentativa de autorização de pagamento, agora ele emite um evento com o resultado da autorização para que o Orquestrador de Criação de Pedidos possa tratar mudança final do status do pedido.
Funcionamento do Padrão SAGA
Como vimos, o padrão de arquitetura SAGA é uma solução para lidar com transações distribuídas em sistemas distribuídos. Ele foi projetado para garantir a consistência dos dados em sistemas distribuídos, mesmo quando as transações acontecem em várias partes do sistema.
Fluxo de Trabalho
O fluxo de trabalho padrão do SAGA é baseado em uma série de etapas que devem ser executadas em sequência.
Cada etapa é responsável por uma parte da transação e pode ser executada em diferentes partes do sistema. As etapas são executada em ordem, e se uma falhar, a transação é revertida para o estado anterior.
Transações
Uma transação é uma operação ou conjunto de operações que garantem a execução completa e consistente de uma tarefa maior, composta por várias operações. Em outras palavras, uma transação é uma tarefa em um conjunto de tarefas que o sistema tem que executar, e ele só considera tudo feito se todas forem concluídas sem problemas.
As transações devem ser atômicas, consistentes, isoladas e duráveis (ACID). As transações dentro de um único serviço são ACID, mas a consistência de dados entre serviços requer uma estratégia de gerenciamento de transações entre serviços.
No padrão SAGA, as transações são gerenciadas por um coordenador que é responsável por iniciar e coordenar a transação. O coordenador inicia a transação criando uma nova instância da transação e executando o primeiro passo. Cada passo pode executar uma ou mais ações, como atualizar um banco de dados ou enviar uma mensagem para outro sistema.
Se um passo falhar, o coordenador reverte a transação para o estado anterior, desfazendo as alterações feitas pelos passos anteriores. Se todos os passos forem concluídos com sucesso, o coordenador confirma a transação, tornando as alterações permanentes.
A Importância das Transações ACID
ACID: Atomicity, Consistency, Isolation, and Durability
Transações ACID garantem a integridade dos dados em sistemas complexos, evitando inconsistências e perdas de informações.
Ao oferecer um conjunto de propriedades confiáveis, as transações ACID asseguram que as operações envolvendo dados sejam concluídas com sucesso, mesmo em cenários de múltiplas transações concorrentes. As propriedades são:
Atomicidade (Atomicity): Garante que uma transação seja tratada como uma operação única e indivisível. Ou seja, todas as ações da transação são concluídas com sucesso, ou nenhuma delas é realizada.
Consistência (Consistency): Assegura que uma transação leve os dados de um estado válido para outro. Isso implica que a execução de uma transação não pode comprometer a consistência global dos dados.
Isolamento (Isolation): Garante que o resultado de uma transação seja invisível para outras transações até que a transação esteja concluída. Isso evita interferências entre transações concorrentes.
Durabilidade (Durability): Garante que as mudanças feitas por uma transação sejam permanentes e persistam, mesmo em caso de falhas no sistema. Os resultados da transação são armazenados de forma permanente.
Rollbacks no padrão Saga
O processo de rollback é iniciado para reverter as etapas já executadas.
No padrão SAGA, o processo de rollback (ou reversão) é acionado quando ocorre uma falha durante a execução de uma transação distribuída. Quando um dos serviços participantes encontra um erro ou uma condição que impede a conclusão bem-sucedida da transação, o processo de rollback é iniciado para reverter as etapas já executadas e restaurar o sistema para um estado consistente.
Durante o processo de rollback, as operações de compensação são acionadas para desfazer as alterações realizadas por cada serviço durante a transação.
Cada serviço é responsável por implementar mecanismos de compensação específicos para reverter as modificações feitas anteriormente. Isso pode envolver a reversão de operações de atualização de dados, cancelamento de ações pendentes ou qualquer outra ação necessária para restaurar o estado consistente do sistema.
O que significa “mecanismo de compensação”? 🤔
Dentro do padrão SAGA, o “mecanismo de compensação” refere-se a um conjunto de operações executadas para reverter ou desfazer as mudanças feitas por uma transação caso ocorra uma falha ou erro durante o processo. Esse mecanismo é projetado para garantir que, se uma etapa de uma transação distribuída não for concluída com sucesso, as ações já realizadas possam ser desfeitas de forma consistente e segura. O mecanismo de compensação é essencial para manter a integridade dos dados e para assegurar que o sistema retorne a um estado consistente, mesmo em situações de interrupções inesperadas ou falhas.
O processo de rollback no padrão SAGA é crucial para garantir a consistência e a integridade dos dados, mesmo em situações de falha durante transações distribuídas.
Exemplo de Rollback
Por exemplo, vamos ver como podemos implementar um modelo de rollback no padrão SAGA para uma compra online em um e-commerce:
1. O cliente faz um pedido no site de comércio eletrônico e fornece suas informações de pagamento
2. O microserviço de checkout de compra do site inicia uma transação local e envia uma solicitação ao microserviço de estoque, pedindo para reservar os itens do carrinho do cliente.
3. O microserviço de estoque inicia uma transação local mas devido a um erro, não consegue garantir a reserva do estoque.
4. O microserviço de estoque envia uma resposta de volta ao microserviço de checkout, indicando que houve uma falha e que ele não conseguiu reservar os itens.
5. O microserviço de checkout recebe a resposta do microserviço de estoque e, executa uma transação de compensação para desfazer as cobranças no método de pagamento do cliente e cancelar o pedido, revertendo efetivamente todo o processo de atendimento.
Commit em duas etapas (Two-Phase commit)
Um padrão comum em arquiteturas SAGA é o “commit em duas etapas” (Two Phase Commit), usado para garantir a consistência das transações distribuídas. Esse padrão opera em duas fases distintas para garantir que todas as partes envolvidas em uma transação concordem em confirmar ou desfazer uma operação de maneira coordenada.
Na primeira fase, o coordenador (geralmente um componente central) envia uma solicitação de comprometimento para todos os participantes da transação.
Os participantes respondem com uma promessa de que estão prontos para confirmar ou desfazer a transação, dependendo da decisão final.
Na segunda fase, o coordenador avalia as respostas dos participantes. Se todos concordarem em confirmar a transação, o coordenador envia uma mensagem de confirmação, e os participantes aplicam permanentemente as alterações. Se algum participante discordar, o coordenador envia uma mensagem de rollback, e todos os participantes revertam as alterações realizadas.
O padrão “commit em duas etapas” fornece um mecanismo para garantir a consistência das transações distribuídas, garantindo que todas as partes envolvidas cheguem a um consenso sobre a confirmação ou rollback de uma transação, mesmo em sistemas distribuídos com múltiplos participantes.
Vantagens e Desvantagens do padrão SAGA
Vantagens
Quando usado no cenário correto, o padrão SAGA apresenta significativas vantagens.
O padrão de arquitetura SAGA apresenta vantagens importantes para garantir integridade de transações em ambientes distribuídos. Algumas dessas vantagens incluem:
Desacoplamento: o SAGA permite que os serviços sejam desacoplados, o que significa que eles podem ser desenvolvidos, testados e implantados de forma independente. Isso torna o desenvolvimento menos propenso a gerar efeitos colaterais indesejados, além de permitir que os serviços sejam escalados de forma mais eficiente.
Tolerância a falhas: o SAGA é projetado para lidar com falhas de forma mais resiliente. Isso significa que, se um serviço falhar, outros serviços podem continuar a funcionar normalmente.
Flexibilidade: o SAGA é flexível e pode ser adaptado a diferentes necessidades. Ele permite que os desenvolvedores escolham a melhor forma de implementar cada serviço, de acordo com as suas necessidades específicas.
Melhor controle de transações: o SAGA permite que as transações sejam gerenciadas de forma mais eficiente, o que pode levar a uma melhor performance e escalabilidade.
Desvantagens
Fique atento as desafios que o modelo SAGA impõe.
Apesar das vantagens, o padrão de arquitetura SAGA também apresenta desvantagens relevantes, que devem ser consideradas antes de se decidir por sua adoção 😥. Algumas dessas desvantagens incluem:
Complexidade: o SAGA pode ser mais complexo do que outros padrões de arquitetura, o que pode tornar o desenvolvimento mais difícil e demorado.
Gerenciamento de estado: o SAGA requer um gerenciamento de estado mais complexo, o que pode levar a problemas de escalabilidade e performance.
Maior sobrecarga: o SAGA pode apresentar uma maior sobrecarga em relação a outros padrões de arquitetura, o que pode afetar a performance do sistema.
Maior complexidade de testes: o SAGA pode apresentar uma maior complexidade de testes, o que pode tornar o processo de desenvolvimento mais demorado e caro.
Aplicações Práticas do Padrão SAGA
E-commerces são um exemplo comum de aplicações que se beneficiam do padrão SAGA.
Uma aplicação prática do padrão SAGA é no desenvolvimento de sistemas distribuídos que envolvam múltiplas etapas para execução de um tarefa, como por exemplo, em comércios eletrônicos.
Em um sistema de comércio eletrônico, muitas transações precisam ser gerenciadas, como a criação de pedidos, o processamento de pagamentos e o envio de produtos. O padrão SAGA pode ser usado para gerenciar essas transações de forma assíncrona e tolerante a falhas, garantindo que todas as etapas da transação sejam concluídas com sucesso ou revertidas em caso de problema.
Outra aplicação prática do padrão SAGA é em sistemas de gerenciamento de pedidos em restaurantes. Em um sistema de gerenciamento de pedidos em restaurantes, transações como a criação de pedidos, a preparação de alimentos e a entrega de pedidos precisam ser gerenciadas.
Em todos esses casos, o padrão SAGA pode ser usado para gerenciar transações de forma assíncrona e tolerante a falhas, garantindo que todas as etapas da transação sejam concluídas com sucesso ou revertidas em caso de situações inesperadas.
Conclusão
Arquitetura SAGA é flexível e pode ser adaptada para diferentes tipos de projetos e requisitos de negócios
Em resumo, a arquitetura SAGA é uma excelente opção para projetos que necessitam lidar com transações distribuídas de forma eficiente. A arquitetura SAGA permite aumentar a escalabilidade e a resiliência do sistema.
Além disso, a arquitetura SAGA é flexível e pode ser adaptada para diferentes tipos de projetos e requisitos de negócios. Com a sua abordagem modular e extensível, a arquitetura SAGA permite que os desenvolvedores criem soluções personalizadas e escaláveis que atendam às necessidades específicas do projeto.
No entanto, é importante notar que a implementação da arquitetura SAGA é mais complexa do que outras abordagens mais tradicionais, especialmente em relação à gestão de transações distribuídas. Portanto, é fundamental que os desenvolvedores tenham um bom entendimento dos conceitos e práticas envolvidos na arquitetura SAGA antes de começar a implementá-la em seus projetos.
Máquina de Estados é uma ferramenta poderosa para modelar sistemas que mudam de estado com base em entradas ou eventos.
Compartilhar
Pedro Mendes Publicado há 9 months atrás.
Máquina de Estados é um conceito fundamental em ciência da computação e engenharia elétrica. É uma ferramenta poderosa para modelar sistemas que mudam de estado com base em entradas ou eventos. Em essência, uma máquina de estados é uma representação matemática de um sistema que pode estar em um número finito de estados diferentes.
Uma máquina de estados pode ser usada para modelar uma ampla variedade de sistemas, desde sistemas simples, como semáforos de trânsito, até sistemas complexos, como sistemas de controle de aviação. Ao modelar um sistema como uma máquina de estados, os engenheiros podem analisar o comportamento do sistema em diferentes estados e prever como ele responderá a diferentes entradas ou eventos. Isso é especialmente útil para sistemas críticos, como sistemas de controle de voo ou sistemas de segurança de usinas nucleares.
Definição de Máquina de Estados
Uma máquina de estados é um modelo matemático usado para representar sistemas que mudam de estado em resposta a eventos externos ou internos. É uma ferramenta útil para projetar e analisar sistemas que envolvem processamento de eventos em tempo real, como sistemas de controle de tráfego aéreo, sistemas de controle de robôs e sistemas de gerenciamento de rede.
Em uma máquina de estados, o sistema é modelado como um conjunto de estados e transições. Cada estado representa uma condição específica do sistema e cada transição representa uma mudança de estado que ocorre em resposta a um evento. Os eventos podem ser gerados internamente pelo sistema ou externamente por um usuário ou outro sistema.
Uma máquina de estados pode ser representada de várias maneiras, incluindo diagramas de estado, tabelas de transição de estado e linguagens de programação específicas de domínio. Cada representação tem suas próprias vantagens e desvantagens e é escolhida com base nas necessidades do sistema em questão.
Ao projetar uma máquina de estados, é importante garantir que ela seja completa e consistente. Isso significa que cada estado deve ser alcançável a partir do estado inicial e que cada evento deve ter uma transição correspondente em cada estado. Além disso, a máquina de estados deve ser capaz de lidar com todos os possíveis eventos que possam ocorrer no sistema.
Em resumo, uma máquina de estados é uma ferramenta valiosa para modelar sistemas que mudam de estado em resposta a eventos. É importante garantir que a máquina de estados seja completa e consistente para garantir que o sistema possa ser projetado e analisado de maneira eficaz.
Funcionamento de uma Máquina de Estados
Uma Máquina de Estados é um modelo computacional que descreve o comportamento de um sistema através de um conjunto de estados e transições entre eles. Essa abordagem é amplamente utilizada em sistemas embarcados e em outras áreas da computação.
Transições de Estado
As transições de estado são as mudanças que ocorrem na Máquina de Estados. Elas são ativadas por eventos de entrada e podem ser condicionais ou não condicionais. As transições não condicionais ocorrem sempre que um evento de entrada é recebido, enquanto as transições condicionais ocorrem apenas se uma condição específica for atendida.
Eventos de Entrada e Saída
Os eventos de entrada são as informações recebidas pela Máquina de Estados. Eles podem ser gerados por sensores, dispositivos externos ou outros sistemas. Os eventos de saída são as ações que a Máquina de Estados executa em resposta aos eventos de entrada. Eles podem ser a ativação de um dispositivo, o envio de um sinal ou a mudança de um estado interno.
A Máquina de Estados pode ser implementada de várias maneiras, incluindo tabelas de estado, diagramas de estado e código estruturado. Cada abordagem tem suas vantagens e desvantagens, e a escolha depende do sistema em questão e das habilidades do desenvolvedor.
Em resumo, a Máquina de Estados é uma ferramenta poderosa para modelar o comportamento de sistemas complexos. Com a compreensão das transições de estado e dos eventos de entrada e saída, é possível criar sistemas robustos e confiáveis.
Tipos de Máquinas de Estados
As máquinas de estados são modelos matemáticos que representam sistemas dinâmicos discretos. Elas são usadas para descrever o comportamento de sistemas que mudam de estado ao longo do tempo, como circuitos eletrônicos, protocolos de rede e sistemas de controle. Existem dois tipos principais de máquinas de estados: finitas e infinitas.
Máquinas de Estados Finitas
As máquinas de estados finitas (MEFs) são sistemas que têm um número finito de estados. Elas são usadas para modelar sistemas que têm um número limitado de comportamentos possíveis. As MEFs são descritas por um conjunto de estados, um conjunto de transições e uma função de transição que mapeia um estado e uma entrada para um novo estado. As MEFs são amplamente utilizadas em projetos de hardware, como a criação de circuitos digitais.
Máquinas de Estados Infinitas
As máquinas de estados infinitas (MEIs) são sistemas que têm um número infinito de estados. Elas são usadas para modelar sistemas que têm um número ilimitado de comportamentos possíveis. As MEIs são descritas por um conjunto de estados, um conjunto de transições e uma função de transição que mapeia um estado e uma entrada para um novo estado. As MEIs são amplamente utilizadas em projetos de software, como a criação de protocolos de rede.
Em resumo, as máquinas de estados são modelos matemáticos que descrevem o comportamento de sistemas dinâmicos discretos. As MEFs são usadas para modelar sistemas com um número limitado de comportamentos possíveis, enquanto as MEIs são usadas para modelar sistemas com um número ilimitado de comportamentos possíveis. Ambos os tipos de máquinas de estados são amplamente utilizados em projetos de hardware e software.
Aplicações Práticas de Máquinas de Estados
Máquinas de estados são amplamente utilizadas em diversas áreas, desde a computação até a engenharia de controle e redes de comunicação. Nesta seção, serão apresentadas algumas aplicações práticas dessas máquinas em cada uma dessas áreas.
Computação
Na computação, as máquinas de estados são muito utilizadas para modelar o comportamento de sistemas de software. Elas são capazes de representar o estado atual de um sistema e as transições que ele pode sofrer a partir de determinadas entradas. Com isso, é possível implementar algoritmos que respondam de forma adequada a diferentes situações.
Alguns exemplos de aplicações práticas de máquinas de estados na computação incluem:
Controle de fluxo de dados em protocolos de comunicação
Análise léxica e sintática em compiladores
Modelagem de comportamento em jogos eletrônicos
Engenharia de Controle
Na engenharia de controle, as máquinas de estados são utilizadas para modelar sistemas dinâmicos e controlá-los de forma eficiente. Elas são capazes de representar o comportamento de sistemas que mudam de estado ao longo do tempo e que podem ser afetados por diferentes entradas.
Alguns exemplos de aplicações práticas de máquinas de estados na engenharia de controle incluem:
Controle de processos industriais, como o controle de temperatura em uma usina de energia
Controle de sistemas de navegação, como o controle de altitude em um avião
Controle de robôs industriais, como o controle de movimento em uma linha de produção
Redes de Comunicação
Nas redes de comunicação, as máquinas de estados são utilizadas para representar o comportamento de protocolos de comunicação. Elas são capazes de representar o estado atual de um protocolo e as transições que ele pode sofrer a partir de determinadas mensagens.
Alguns exemplos de aplicações práticas de máquinas de estados em redes de comunicação incluem:
Protocolos de roteamento em redes de computadores
Protocolos de controle de congestionamento em redes de comunicação
Protocolos de controle de acesso ao meio em redes sem fio
Nós utilizamos cookies para garantir que você tenha a melhor experiência em nosso site. Se você continua a usar este site, assumimos que você está satisfeito.Ok