
O padrão de arquitetura SAGA é um modelo que tem como objetivo simplificar a implementação de sistemas distribuídos, robustos e escaláveis.
O padrão SAGA foi inicialmente proposto para lidar com transações distribuídas em sistemas, mas pode ser aplicado em uma variedade de cenários. Ele se concentra em dividir as transações em etapas atômicas que podem ser desfeitas ou revertidas se algo der errado. Isso ajuda a garantir que os sistemas sejam consistentes e confiáveis, mesmo em ambientes complexos.
A implementação do padrão SAGA envolve a criação de uma máquina de estado que gerencia as transações e as etapas atômicas. Cada etapa é executada como uma transação separada e pode ser revertida se ocorrer um erro. Isso permite que os sistemas sejam altamente disponíveis e tolerantes a falhas, enquanto ainda mantêm a consistência dos dados.
Entendendo o Padrão de Arquitetura SAGA
O padrão SAGA é um modelo arquitetural de aplicações que foi desenvolvido para lidar com problemas de transações distribuídas. Ele é especialmente útil para aplicações que exigem uma alta consistência de dados.
Ele estabelece uma técnica de gerenciamento de transações que registra cada operação que é executada em um sistema distribuído. Cada operação é composta por várias etapas, que podem ser executadas em diferentes serviços.
Uma das principais vantagens do padrão de arquitetura SAGA é que ele permite que as operação sejam executadas de forma assíncrona 👈, o que significa que cada etapa pode ser executada em seu próprio serviço. Isso pode melhorar significativamente a escalabilidade e a flexibilidade do sistema.
Outra vantagem do padrão de arquitetura SAGA é que ele permite que as transações sejam revertidas de forma segura. Se uma etapa da transação falhar, o sistema pode reverter todas as etapas anteriores de forma segura, garantindo que o sistema permaneça em um estado consistente.
No entanto, o padrão de arquitetura SAGA também apresenta alguns desafios. Por exemplo, a implementação do padrão pode ser complexa e requer um bom entendimento de como as transações distribuídas funcionam 😬. Além disso, a implementação de transações reversíveis pode ser difícil em alguns casos.
Origem

O aumento no interesse do padrão SAGA pode ser atribuído à evolução das arquiteturas de microsserviços e sistemas distribuídos de grande escala. Porém, as bases do SAGA nascem bem antes: o primeiro estudo sobre o padrão aparece em 1987 em um paper da Universidade Princeton chamado “SAGAS”.

Long Lived Transactions (LLTs)
Com o aumento da complexidade das aplicações distribuídas, surgiram desafios significativos relacionados à consistência de dados e ao gerenciamento de transações em vários serviços interconectados.
Diante desses desafios, os desenvolvedores e arquitetos de sistemas buscaram uma abordagem mais eficaz para resolver tais problemas.
Assim, o padrão SAGA surgiu como uma resposta para atender a essas necessidades, fornecendo uma estrutura flexível e confiável para o gerenciamento de transações distribuídas e operações assíncronas em sistemas complexos.
SAGA e arquiteturas baseadas em eventos

Uma arquitetura baseada em eventos é um modelo de design de software em que os componentes do sistema se comunicam e reagem a eventos gerados interna ou externamente.
Nessa arquitetura, os eventos são usados como a principal forma de comunicação entre os diferentes serviços ou componentes do sistema. Esses eventos podem representar ações significativas, mudanças de estado ou ocorrências importantes no ambiente operacional.
A arquitetura baseada em eventos é projetada para facilitar a escalabilidade, a flexibilidade e a capacidade de resposta do sistema, permitindo que os componentes se comuniquem de maneira assíncrona e reajam a mudanças em tempo real.
O padrão SAGA se torna ainda mais robusto nas arquiteturas baseadas em eventos, mas é possível implementar o SAGA em uma arquitetura de comunicação síncrona.
Transações Distribuídas

Tanto a arquitetura SAGA quanto a arquitetura baseada em eventos estão focadas na execução de transações distribuídas em sistemas complexos.
A arquitetura baseada em eventos foca na comunicação e propagação eficiente de eventos dentro do sistema, permitindo que os diferentes componentes reajam a mudanças e atualizações de maneira oportuna.
No padrão SAGA, temos um modelo ainda mais focado na coordenação de operações de compensação e progresso de transações. Veremos mais detalhes no decorrer do post.
Resiliência e Flexibilidade do Sistema

Tanto a arquitetura SAGA quanto a arquitetura baseada em eventos contribuem para a resiliência e flexibilidade geral dos serviços, pois permitem que cada um consiga lidar com sua carga de trabalho de forma independente dos demais.
A combinação dessas abordagens reforça a capacidade do sistema de lidar com situações imprevistas e de se adaptar a mudanças.
Componentes do Padrão SAGA
A depender do modelo de solução usado no padrão arquitetura SAGA, podemos encontrar diferentes componentes:
Serviços

Os serviços são os componentes básicos do modelo SAGA. Eles realizam as operações de negócios em uma transação distribuída. Cada serviço é responsável por uma parte específica da transação e deve ser projetado para ser independente e escalável.
Os serviços podem ser implementados usando qualquer tecnologia de sua escolha, desde que sigam padrões de design para garantir a escalabilidade e a resiliência. Eles devem ser projetados para serem altamente disponíveis e capazes de lidar com grandes volumes de tráfego.
Broker de Mensagens

Um broker de mensagens desempenha um papel crucial na arquitetura SAGA baseada em eventos, atuando como um intermediário confiável para facilitar a comunicação assíncrona entre os diferentes serviços e componentes distribuídos.
Ao permitir o envio e recebimento de mensagens entre os vários participantes de uma transação, o broker de mensagens permite a troca de informações de forma confiável e segura, essencial para o funcionamento coordenado das transações distribuídas no contexto do padrão SAGA.
Além disso, o broker de mensagens oferece suporte para controle e encaminhamento de eventos e mensagens em tempo real, garantindo que as diferentes etapas de uma transação sejam executadas de forma previsível.
Com recursos avançados de gerenciamento de filas e tópicos, o broker de mensagens permite que os serviços distribuídos coordenem suas operações de forma eficaz, garantindo a consistência e a integridade dos dados durante todo o processo de transação.
Broker de mensagens usados
As principais tecnologias de mercado frequentemente utilizadas como Broker de Mensagens no padrão SAGA são:
- Apache Kafka
- RabbitMQ
- ActiveMQ
- Redis Pub/Sub
- Amazon Simple Notification Service (SNS) e Simple Queue Service (SQS)
- Apache Pulsar
- Google Cloud Pub/Sub
- Microsoft Azure Service Bus
Padrões de implementação do Padrão SAGA
Ao implementar o padrão SAGA em sistemas distribuídos, os desenvolvedores têm a opção de escolher entre dois principais modelos de implementação: Coreografia e Orquestração. Cada um desses modelos apresenta vantagens e desafios distintos, oferecendo abordagens diferentes para lidar com transações distribuídas e o efeitos colaterais delas.
Coreografia

Em uma arquitetura SAGA baseada em coreografia, as diferentes etapas de uma transação são coordenadas entre os vários serviços envolvidos. Em vez de um componente centralizado controlar todo o processo, cada serviço participante mantém o conhecimento sobre suas próprias responsabilidades e interações com outros serviços.
Quando uma transação é iniciada, cada serviço realiza sua parte das operações e notifica os outros serviços sobre o progresso, geralmente utilizando um broker de mensagens. Essa troca de informações entre os serviços permite que cada um saiba quando é apropriado avançar para a próxima etapa da transação ou se é necessário realizar operações de compensação, caso ocorram problemas.
A arquitetura de coreografia SAGA permite uma comunicação direta e descentralizada entre os serviços, garantindo que a transação avance de forma fluida e consistente.
Essa abordagem descentralizada oferece maior flexibilidade e escalabilidade para lidar com transações distribuídas em sistemas que envolvem múltiplos serviços interconectados.
Exemplos de Coreografia
Exemplo de arquitetura SAGA usando Coreografia 🤓

Nesse exemplo, temos a seguinte ordem:
- O Serviço de Pedidos cria um registro do
Pedidocom um statusPendente. - Nesse momento, o Serviço de Pedidos informa ao Serviço de Pagamento sobre o pedido e espera até a obter uma resposta de
sucessooufalha.
- O Serviço de Pagamento realiza a tentativa de autorização de pagamento e retorna o resultado para o Serviço de Pedidos. O Serviço de Pedidos por sua vez deve atualizar o status do pedido de acordo com o sucesso ou falha do pagamento.
Exemplo de arquitetura SAGA usando Coreografia com Eventos 🤓
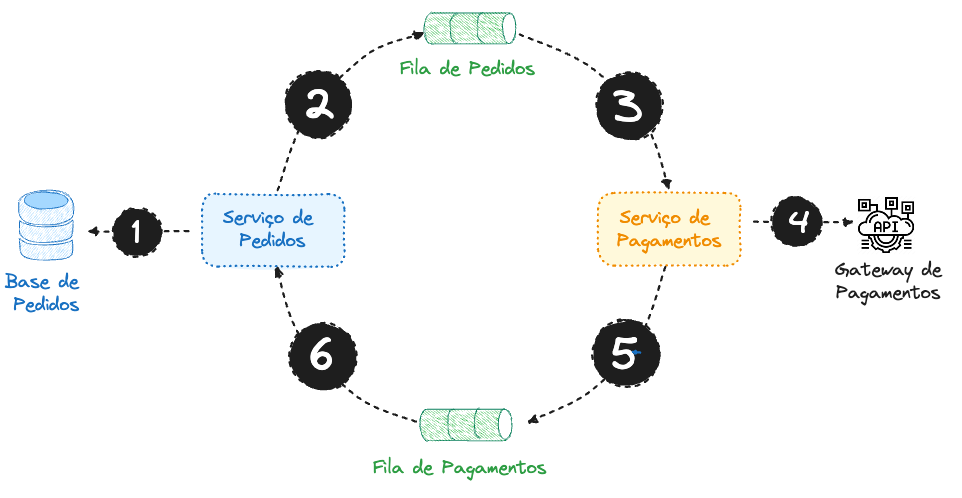
Nesse exemplo, temos a seguinte ordem:
- O Serviço de Pedidos cria um registro do
Pedidocom um statusPendente. - Nesse momento, o Serviço de Pedidos emite o evento de
Pedido Criadoe disponibiliza naFila de Pedidos.
- O Serviço de Pagamento é notificado de um novo pedido.
- O Serviço de Pagamento realiza a tentativa de autorização de pagamento.
- O Serviço de Pagamento emite um evento para a
Fila de Pagamentoscom o resultado da autorização de pagamento.
- O Serviço de Pedidos agora é notificado com o resultado da tentativa de pagamento, e deve atualizar o status do pedido de acordo com o sucesso ou falha do pagamento.
Orquestração

Em um modelo de arquitetura SAGA baseado em orquestração, o orquestrador é responsável por coordenar as transações distribuídas entre os diferentes serviços. Ele é o ponto central da arquitetura SAGA e garante que todas as transações sejam concluídas com sucesso ou revertidas em caso de falha.
O orquestrador é responsável por acionar o fluxo compensação para reverter transações em caso de falha. Isso significa que, se um serviço falhar durante uma transação, o orquestrador executará uma série de operações para reverter as alterações feitas pelos Serviços que já foram executados.
Exemplos de Orquestração
Exemplo de arquitetura SAGA usando Orquestração 🤓

Nesse exemplo, temos a seguinte ordem:
- O Orquestrador de Criação de Pedidos é chamado.
- O Orquestrador de Criação de Pedidos chama o Serviço de Pedidos informando sobre a criação do
pedidoe espera até obter uma resposta desucessoouerro.
- Em caso de sucesso, o Orquestrador de Criação de Pedidos chama o Serviço de Pagamentos e aguarda até obter uma resposta da transação para atualizar o
pedidode acordo com o pagamento.
Exemplo de arquitetura SAGA usando Orquestração com Eventos 🤓

Nesse exemplo, temos a seguinte ordem:
- O Orquestrador de Criação de Pedidos é chamado.
- O Orquestrador de Criação de Pedidos emite um evento para a
Fila de Criação de Serviço, e o Serviço de Pedidos deve consumir e criar opedido.
- Ao criar o
pedido, o Serviço de Pedidos emite o evento dePedido Criadoe disponibiliza naFila de Pedidos Criados.
- Após ouvir a emissão de pedido criado, o Orquestrador de Criação de Pedidos deve dar continuidade ao processo, agora emitindo um evento de “Autorização de Pagamento”. O Serviço de Pagamento é notificado de um novo
pedido.
- Após o Serviço de Pagamento realizar a tentativa de autorização de pagamento, agora ele emite um evento com o resultado da autorização para que o Orquestrador de Criação de Pedidos possa tratar mudança final do status do
pedido.
Funcionamento do Padrão SAGA
Como vimos, o padrão de arquitetura SAGA é uma solução para lidar com transações distribuídas em sistemas distribuídos. Ele foi projetado para garantir a consistência dos dados em sistemas distribuídos, mesmo quando as transações acontecem em várias partes do sistema.
Fluxo de Trabalho
O fluxo de trabalho padrão do SAGA é baseado em uma série de etapas que devem ser executadas em sequência.
Cada etapa é responsável por uma parte da transação e pode ser executada em diferentes partes do sistema. As etapas são executada em ordem, e se uma falhar, a transação é revertida para o estado anterior.
Transações
Uma transação é uma operação ou conjunto de operações que garantem a execução completa e consistente de uma tarefa maior, composta por várias operações. Em outras palavras, uma transação é uma tarefa em um conjunto de tarefas que o sistema tem que executar, e ele só considera tudo feito se todas forem concluídas sem problemas.
As transações devem ser atômicas, consistentes, isoladas e duráveis (ACID). As transações dentro de um único serviço são ACID, mas a consistência de dados entre serviços requer uma estratégia de gerenciamento de transações entre serviços.
No padrão SAGA, as transações são gerenciadas por um coordenador que é responsável por iniciar e coordenar a transação. O coordenador inicia a transação criando uma nova instância da transação e executando o primeiro passo. Cada passo pode executar uma ou mais ações, como atualizar um banco de dados ou enviar uma mensagem para outro sistema.
Se um passo falhar, o coordenador reverte a transação para o estado anterior, desfazendo as alterações feitas pelos passos anteriores. Se todos os passos forem concluídos com sucesso, o coordenador confirma a transação, tornando as alterações permanentes.
A Importância das Transações ACID

Transações ACID garantem a integridade dos dados em sistemas complexos, evitando inconsistências e perdas de informações.
Ao oferecer um conjunto de propriedades confiáveis, as transações ACID asseguram que as operações envolvendo dados sejam concluídas com sucesso, mesmo em cenários de múltiplas transações concorrentes. As propriedades são:
- Atomicidade (Atomicity): Garante que uma transação seja tratada como uma operação única e indivisível. Ou seja, todas as ações da transação são concluídas com sucesso, ou nenhuma delas é realizada.
- Consistência (Consistency): Assegura que uma transação leve os dados de um estado válido para outro. Isso implica que a execução de uma transação não pode comprometer a consistência global dos dados.
- Isolamento (Isolation): Garante que o resultado de uma transação seja invisível para outras transações até que a transação esteja concluída. Isso evita interferências entre transações concorrentes.
- Durabilidade (Durability): Garante que as mudanças feitas por uma transação sejam permanentes e persistam, mesmo em caso de falhas no sistema. Os resultados da transação são armazenados de forma permanente.
Rollbacks no padrão Saga

No padrão SAGA, o processo de rollback (ou reversão) é acionado quando ocorre uma falha durante a execução de uma transação distribuída. Quando um dos serviços participantes encontra um erro ou uma condição que impede a conclusão bem-sucedida da transação, o processo de rollback é iniciado para reverter as etapas já executadas e restaurar o sistema para um estado consistente.
Durante o processo de rollback, as operações de compensação são acionadas para desfazer as alterações realizadas por cada serviço durante a transação.
Cada serviço é responsável por implementar mecanismos de compensação específicos para reverter as modificações feitas anteriormente. Isso pode envolver a reversão de operações de atualização de dados, cancelamento de ações pendentes ou qualquer outra ação necessária para restaurar o estado consistente do sistema.
O que significa “mecanismo de compensação”? 🤔
Dentro do padrão SAGA, o “mecanismo de compensação” refere-se a um conjunto de operações executadas para reverter ou desfazer as mudanças feitas por uma transação caso ocorra uma falha ou erro durante o processo. Esse mecanismo é projetado para garantir que, se uma etapa de uma transação distribuída não for concluída com sucesso, as ações já realizadas possam ser desfeitas de forma consistente e segura. O mecanismo de compensação é essencial para manter a integridade dos dados e para assegurar que o sistema retorne a um estado consistente, mesmo em situações de interrupções inesperadas ou falhas.
O processo de rollback no padrão SAGA é crucial para garantir a consistência e a integridade dos dados, mesmo em situações de falha durante transações distribuídas.
Exemplo de Rollback
Por exemplo, vamos ver como podemos implementar um modelo de rollback no padrão SAGA para uma compra online em um e-commerce:
1. O cliente faz um pedido no site de comércio eletrônico e fornece suas informações de pagamento


2. O microserviço de checkout de compra do site inicia uma transação local e envia uma solicitação ao microserviço de estoque, pedindo para reservar os itens do carrinho do cliente.
3. O microserviço de estoque inicia uma transação local mas devido a um erro, não consegue garantir a reserva do estoque.


4. O microserviço de estoque envia uma resposta de volta ao microserviço de checkout, indicando que houve uma falha e que ele não conseguiu reservar os itens.
5. O microserviço de checkout recebe a resposta do microserviço de estoque e, executa uma transação de compensação para desfazer as cobranças no método de pagamento do cliente e cancelar o pedido, revertendo efetivamente todo o processo de atendimento.

Commit em duas etapas (Two-Phase commit)
Um padrão comum em arquiteturas SAGA é o “commit em duas etapas” (Two Phase Commit), usado para garantir a consistência das transações distribuídas. Esse padrão opera em duas fases distintas para garantir que todas as partes envolvidas em uma transação concordem em confirmar ou desfazer uma operação de maneira coordenada.
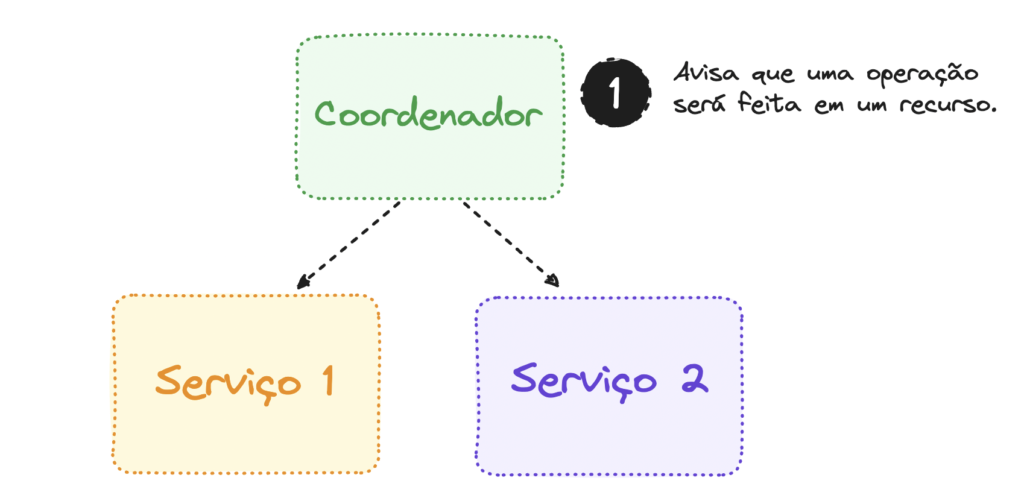
Na primeira fase, o coordenador (geralmente um componente central) envia uma solicitação de comprometimento para todos os participantes da transação.
Os participantes respondem com uma promessa de que estão prontos para confirmar ou desfazer a transação, dependendo da decisão final.

Na segunda fase, o coordenador avalia as respostas dos participantes. Se todos concordarem em confirmar a transação, o coordenador envia uma mensagem de confirmação, e os participantes aplicam permanentemente as alterações. Se algum participante discordar, o coordenador envia uma mensagem de rollback, e todos os participantes revertam as alterações realizadas.

O padrão “commit em duas etapas” fornece um mecanismo para garantir a consistência das transações distribuídas, garantindo que todas as partes envolvidas cheguem a um consenso sobre a confirmação ou rollback de uma transação, mesmo em sistemas distribuídos com múltiplos participantes.
Vantagens e Desvantagens do padrão SAGA
Vantagens

O padrão de arquitetura SAGA apresenta vantagens importantes para garantir integridade de transações em ambientes distribuídos. Algumas dessas vantagens incluem:
- Desacoplamento: o SAGA permite que os serviços sejam desacoplados, o que significa que eles podem ser desenvolvidos, testados e implantados de forma independente. Isso torna o desenvolvimento menos propenso a gerar efeitos colaterais indesejados, além de permitir que os serviços sejam escalados de forma mais eficiente.
- Tolerância a falhas: o SAGA é projetado para lidar com falhas de forma mais resiliente. Isso significa que, se um serviço falhar, outros serviços podem continuar a funcionar normalmente.
- Flexibilidade: o SAGA é flexível e pode ser adaptado a diferentes necessidades. Ele permite que os desenvolvedores escolham a melhor forma de implementar cada serviço, de acordo com as suas necessidades específicas.
- Melhor controle de transações: o SAGA permite que as transações sejam gerenciadas de forma mais eficiente, o que pode levar a uma melhor performance e escalabilidade.
Desvantagens

Apesar das vantagens, o padrão de arquitetura SAGA também apresenta desvantagens relevantes, que devem ser consideradas antes de se decidir por sua adoção 😥. Algumas dessas desvantagens incluem:
- Complexidade: o SAGA pode ser mais complexo do que outros padrões de arquitetura, o que pode tornar o desenvolvimento mais difícil e demorado.
- Gerenciamento de estado: o SAGA requer um gerenciamento de estado mais complexo, o que pode levar a problemas de escalabilidade e performance.
- Maior sobrecarga: o SAGA pode apresentar uma maior sobrecarga em relação a outros padrões de arquitetura, o que pode afetar a performance do sistema.
- Maior complexidade de testes: o SAGA pode apresentar uma maior complexidade de testes, o que pode tornar o processo de desenvolvimento mais demorado e caro.
Aplicações Práticas do Padrão SAGA

Uma aplicação prática do padrão SAGA é no desenvolvimento de sistemas distribuídos que envolvam múltiplas etapas para execução de um tarefa, como por exemplo, em comércios eletrônicos.
Em um sistema de comércio eletrônico, muitas transações precisam ser gerenciadas, como a criação de pedidos, o processamento de pagamentos e o envio de produtos. O padrão SAGA pode ser usado para gerenciar essas transações de forma assíncrona e tolerante a falhas, garantindo que todas as etapas da transação sejam concluídas com sucesso ou revertidas em caso de problema.
Outra aplicação prática do padrão SAGA é em sistemas de gerenciamento de pedidos em restaurantes. Em um sistema de gerenciamento de pedidos em restaurantes, transações como a criação de pedidos, a preparação de alimentos e a entrega de pedidos precisam ser gerenciadas.
Em todos esses casos, o padrão SAGA pode ser usado para gerenciar transações de forma assíncrona e tolerante a falhas, garantindo que todas as etapas da transação sejam concluídas com sucesso ou revertidas em caso de situações inesperadas.
Conclusão

Em resumo, a arquitetura SAGA é uma excelente opção para projetos que necessitam lidar com transações distribuídas de forma eficiente. A arquitetura SAGA permite aumentar a escalabilidade e a resiliência do sistema.
Além disso, a arquitetura SAGA é flexível e pode ser adaptada para diferentes tipos de projetos e requisitos de negócios. Com a sua abordagem modular e extensível, a arquitetura SAGA permite que os desenvolvedores criem soluções personalizadas e escaláveis que atendam às necessidades específicas do projeto.
No entanto, é importante notar que a implementação da arquitetura SAGA é mais complexa do que outras abordagens mais tradicionais, especialmente em relação à gestão de transações distribuídas. Portanto, é fundamental que os desenvolvedores tenham um bom entendimento dos conceitos e práticas envolvidos na arquitetura SAGA antes de começar a implementá-la em seus projetos.
Links Úteis
- Microsoft Azure – Transações distribuídas do Saga
- Microservices.io – SAGA Pattern
- AWS – Saga Pattern
- AWS – Building a serverless distributed application using a saga orchestration pattern
- IBM Architecture Center – Saga Pattern
- Red Hat – The pros and cons of the Saga Architecture Pattern























